
Effective Practices for Mocking LLM Responses During the Software Development Lifecycle

# LLMs
# Software Development
# AGIFlow
Boosting Productivity and Ensuring Reliability in LLM Applications with Strategic Testing and Mocking Techniques
July 10, 2024
Vuong Ngo

After a few years of experimenting with large language models (LLMs) with Proof of Concepts (POCs), the challenge now is getting those products ready for production. Applying rigorous engineering practices and ensuring comprehensive testing at various levels is crucial to prevent live issues and regressions. A key strategy is implementing extensive unit tests and mock testing to verify the application’s behavior. However, traditional testing methods are often insufficient due to the complexity of different APIs, tools in the LLM stack, and the inherent randomness of LLM responses. This article will discuss the fundamentals of mocking techniques in LLM testing, highlighting strategies that not only facilitate development but also ensure the entire application functions correctly in a production environment.
Challenges and Trade-offs of LLM Testing using Traditional Method
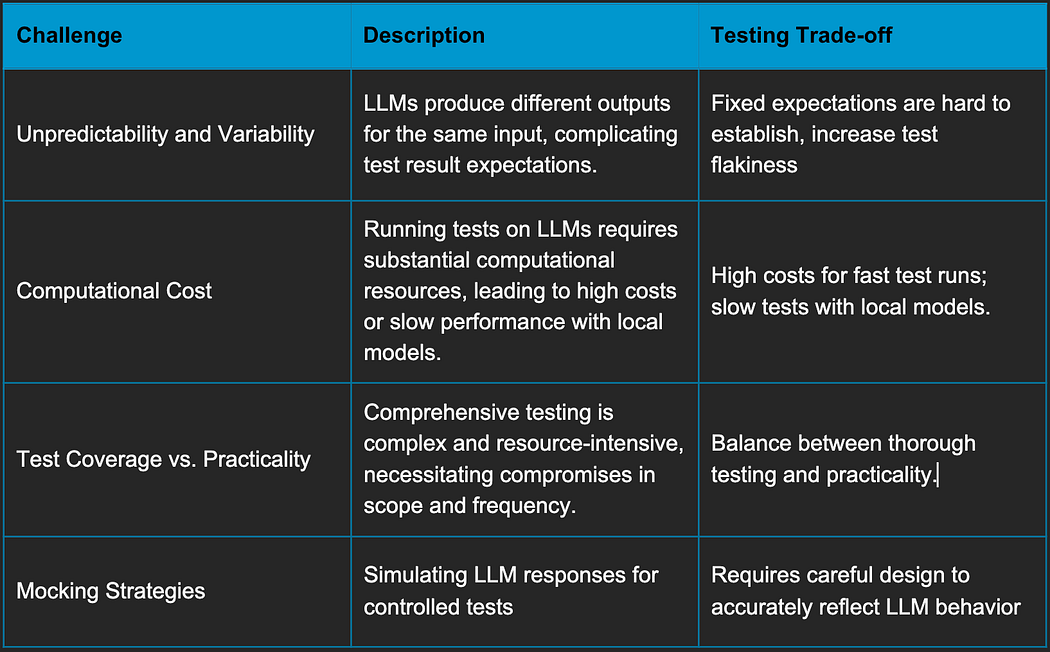
Testing large language models (LLMs) presents unique challenges that diverge from traditional software testing paradigms. One significant issue is the unpredictability and variability of LLM responses. Unlike deterministic systems, LLMs can produce different outputs for the same input, making it difficult to establish fixed expectations for test results. This variability complicates the implementation of both Test-Driven Development (TDD) and Behavior-Driven Development (BDD), as tests may not consistently yield the same outcomes. Moreover, LLMs models requires substantial computational resources. Running tests on these models can be prohibitively expensive if fast responses are needed, or alternatively, very slow when using more cost-effective, open-source models locally.
The trade-offs in LLM testing are multifaceted. To achieve rapid response times, we might opt for cloud-based solutions with robust infrastructure, but this incurs high costs, especially for continuous integration and delivery pipelines. Conversely, using open-source models locally can significantly reduce costs but at the expense of speed and scalability, which may hinder development velocity. Another trade-off is the balance between test coverage and practicality. Comprehensive testing, including unit tests, integration tests, and end-to-end tests, is essential for reliable production deployment. However, the complexity and resource intensity of LLMs often necessitate compromises in test scope and frequency. Implementing effective mocking strategies can mitigate some of these issues by simulating LLM responses, allowing for more controlled and repeatable tests, but this approach requires careful design to ensure it accurately reflects real-world behavior.
Why Shouldn’t We Mock LLM Responses?
Mocking LLM responses is often ineffective due to the inherent non-deterministic nature of these models. Unlike traditional software systems that produce consistent outputs for given inputs, LLMs can generate a wide range of responses, even when queried with the same prompt. This variability poses significant challenges for mocking methods, which typically rely on predictable and repeatable outputs.
- Non-Deterministic Outputs: LLMs generate responses based on probability distributions, which means the same input can yield different outputs each time. Mocking these responses would fail to capture the full spectrum of potential behaviors, leading to an inaccurate representation of the model’s capabilities and limitations.
- Complex Interactions: The interactions within LLMs are highly complex, involving large amounts of contextual data and nuanced understanding. Mocking simplifies these interactions, potentially missing critical edge cases and nuanced behaviors that could affect real-world performance.
- Resource Intensive: Effective mocking requires extensive pre-processing and storage of possible outputs, which can be resource-intensive and impractical for large-scale LLMs. This approach can also lead to maintenance overhead, as the mocks need to be updated frequently to reflect the evolving nature of the models.
Alternative Methods for Testing, Benchmarking, and Evaluating LLMs
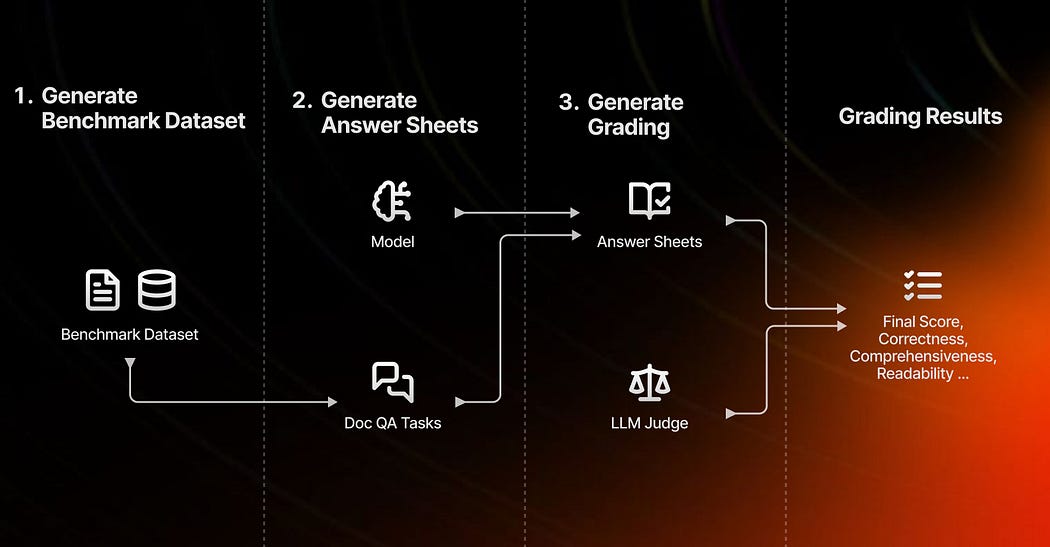
Instead of relying on mocks, there are more robust and effective methods for testing, benchmarking, and evaluating LLMs:
- Golden Data Benchmarks: Utilize curated datasets with known outcomes to benchmark LLM performance. These datasets provide a standard reference point, enabling consistent and reliable comparisons across different models and iterations.
- Cross-Model Evaluations: Use other LLMs to evaluate responses. By comparing the outputs of different models, you can gain insights into the strengths and weaknesses of each, helping to identify areas for improvement.
- Probabilistic Assertions: Implement probabilistic assertions that evaluate the likelihood of different responses. This approach acknowledges the inherent variability of LLMs and focuses on the distribution of plausible outputs rather than fixed results.
Human-in-the-loop evaluation and continuous monitoring are other techniques which should be used on production. These alternative methods provide a more accurate and holistic assessment of LLM capabilities, ensuring that models perform reliably in diverse and unpredictable real-world scenarios.
When Should We Mock LLM Responses?
Mocking LLM responses can be highly beneficial in specific scenarios, particularly when the goal is to enhance development efficiency and reduce costs. Here are some key situations where mocking LLM responses is advantageous:
Developing Libraries and Frameworks Independent of LLM Responses
When building tools such as observability and tracing libraries for LLMs, testing various data responses from multiple providers can be impractical and expensive. Mocking responses allows developers to simulate a wide range of scenarios without incurring the cost of actual LLM invocations. This approach ensures that the library can handle diverse outputs and edge cases, facilitating thorough testing and high development velocity.
- Easily produce different types of responses
- Test library robustness without high costs
- Maintain high development velocity
Unblocking Other Developers
In collaborative development environments, dependencies between team members can cause delays. For instance, if a UI developer is waiting for an API to be completed, providing a working API with mocked LLM responses can keep the project moving forward. This allows the team to develop and test UI components in parallel, ensuring timely completion of tasks.
- Provide working API with mocked responses
- Allow parallel development and testing
- Ensure timely task completion
Saving Money
Continuous integration and continuous delivery (CI/CD) pipelines often involve frequent testing of new changes. Running tests on live LLMs for each change can be prohibitively expensive, especially for large teams. Using mocked responses for regression tests helps streamline the CI/CD process, saving significant costs while ensuring that unchanged code does not repeatedly incur unnecessary expenses.
- Avoid costly live LLM invocations in CI/CD
- Use mock responses for regression tests
- Streamline CI/CD process and save costs
Handling Flaky CI/CD
LLMs can introduce inconsistency in CI/CD workflows, resulting in flaky tests. By isolating LLM evaluations and using mock responses for user flow and integration testing, teams can reduce the impact of these inconsistencies. Incorporating human-in-the-loop testing and review for final benchmarking ensures that the critical aspects of LLM performance are accurately assessed without compromising the stability of the CI/CD pipeline.
- Reduce inconsistent CI/CD results
- Isolate LLM evaluations for stability
- Use mocks for user flow and integration testing
By strategically using mock LLM responses, development teams can maintain high productivity, control costs, and ensure robust testing practices, ultimately leading to more reliable and efficient development cycles.
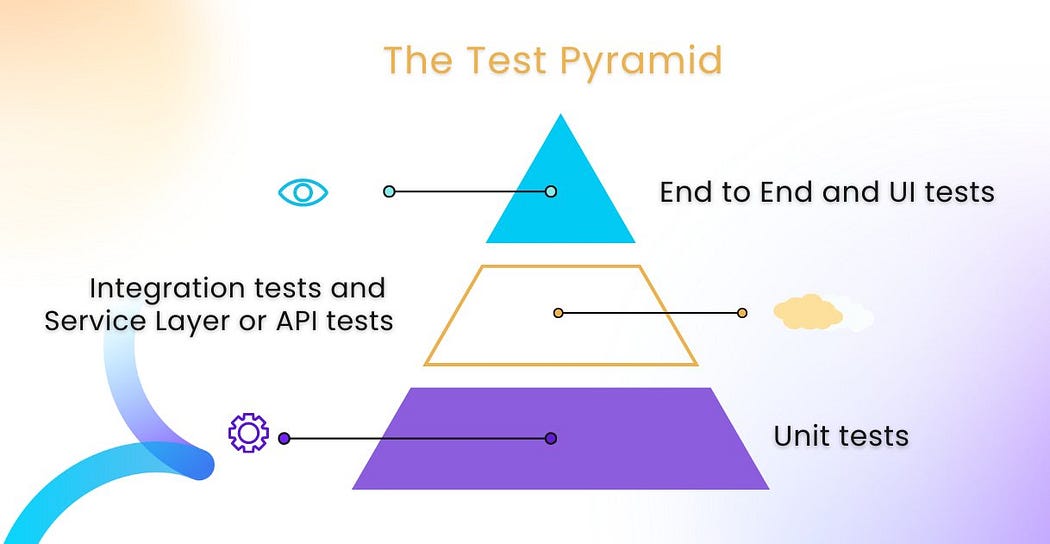
Image from https://www.testevolve.com/blog/the-testing-pyramid-an-essential-strategy-for-agile-testing
How to Mock LLM Responses?
That’s enough theory, show me some codes on how to do it!
1. Identify Levels of Mocking
When mocking, it’s crucial not to interfere with the internal implementation of libraries or frameworks, as these are prone to changes that can disrupt your pipeline. Instead, focus on mocking at higher levels, such as the APIs you consume or bare metal as the network requests, to minimize potential disruptions. Here are two coding examples illustrating these principles:
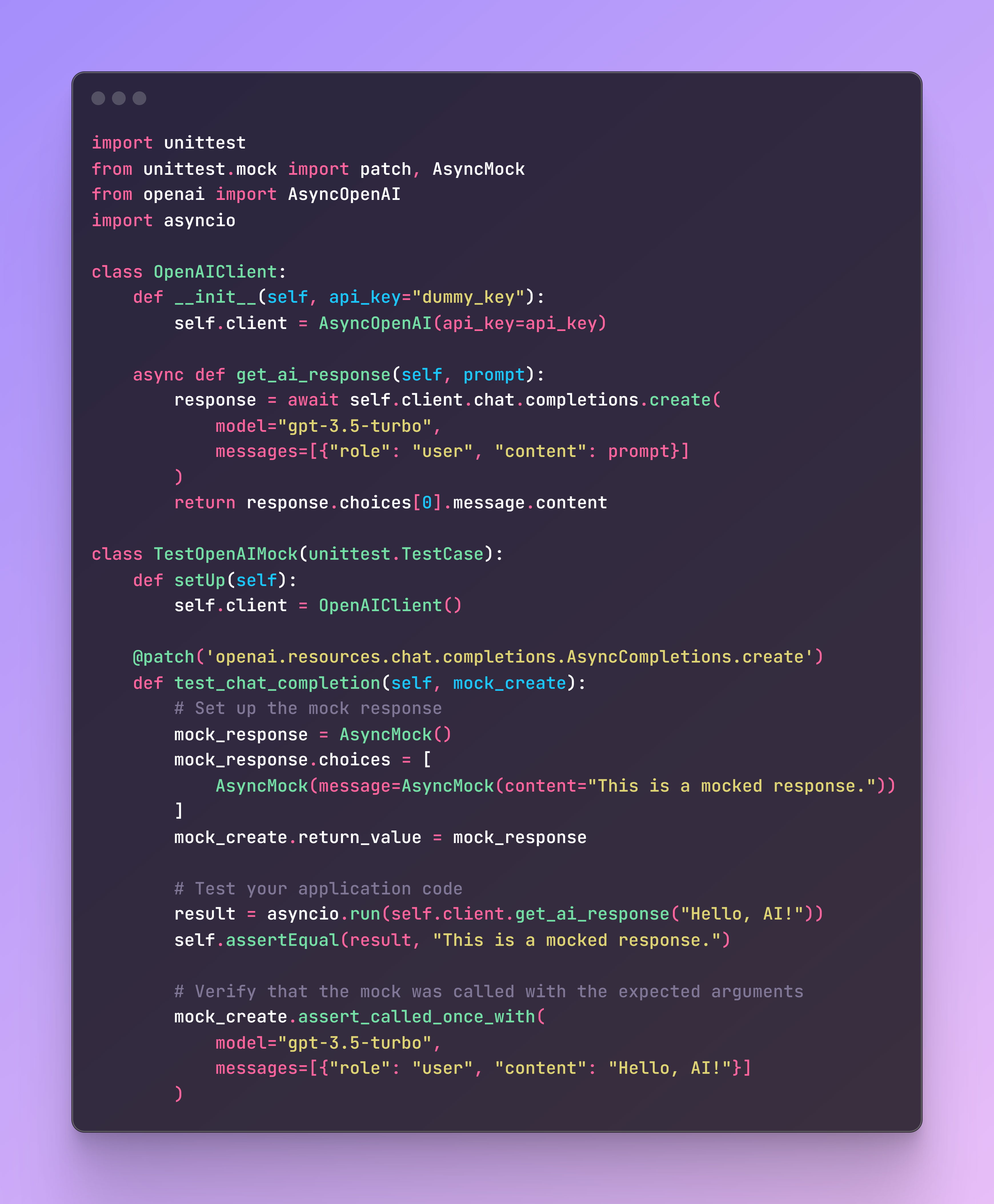
Option A: Mocking libraries’ methodMocking the response directly from the OpenAI library can help you test your application logic without making actual API calls. Below is an example using Python’s unittest.mock module to mock an OpenAI chat completion response.
Option B: Mocking Network Request
Mocking the network request itself is another effective way to test your application. This example uses the responses library to mock the HTTP call to the OpenAI API.
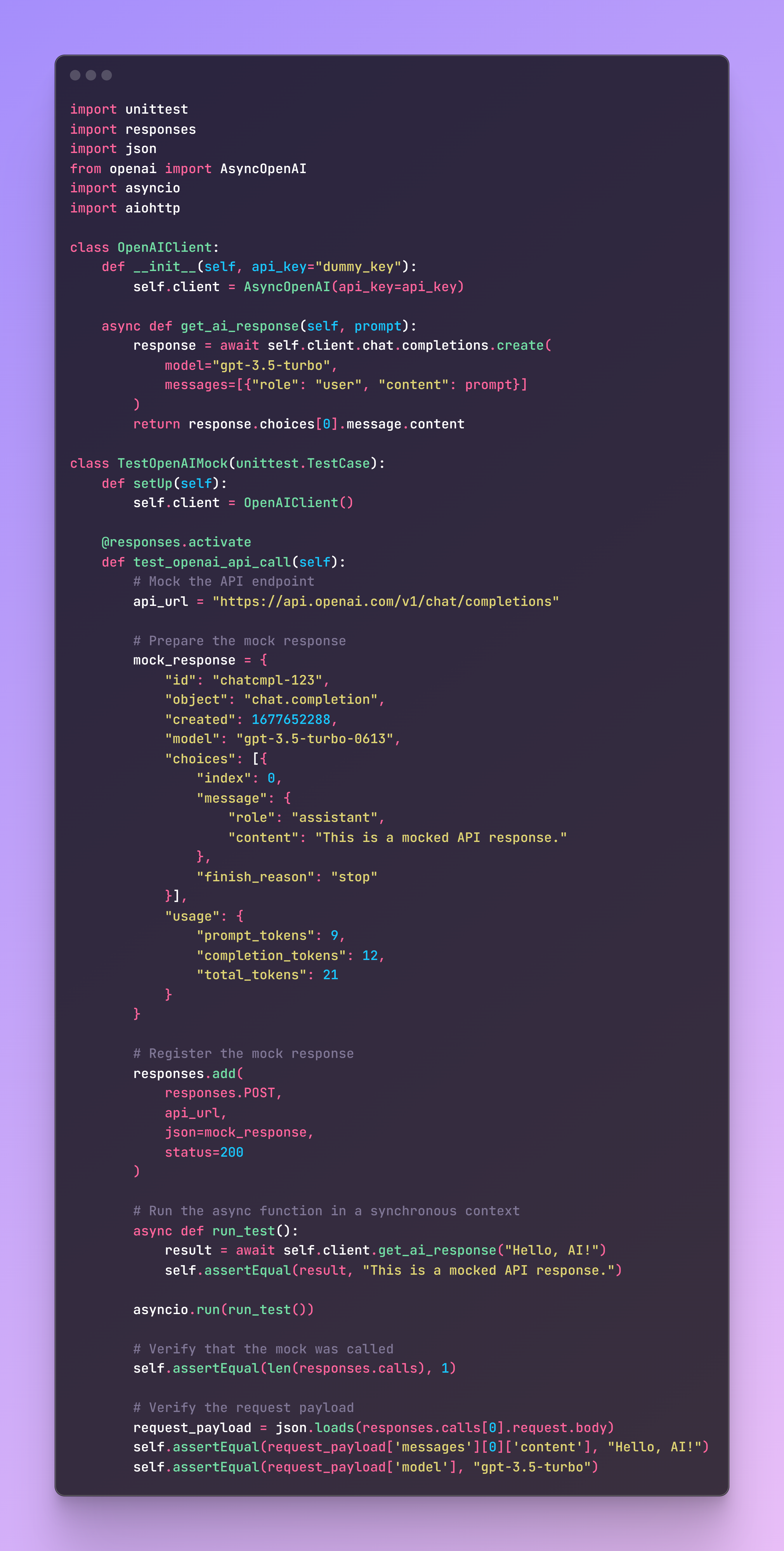
By mocking at these levels, you can effectively test your application while avoiding the pitfalls associated with changes in underlying libraries or frameworks. This approach ensures your tests remain stable and reliable over time.
2. Create Mock Data
Generating a comprehensive set of mock responses for your LLM is essential to ensure thorough testing and validation of your application. These mock responses should cover a wide range of scenarios, including both typical interactions and edge cases. This approach guarantees that your application can handle various situations effectively. You can use a fixed set of responses, record real API calls, or leverage libraries like faker to introduce randomization. Here are three examples demonstrating these methods:
Example A: Generating a Fixed Set of Mock DataUsing a fixed set of responses allows for consistent and repeatable testing. Simply use a dictionary or list to store response, and select the corresponding item based on request. Here’s an example:
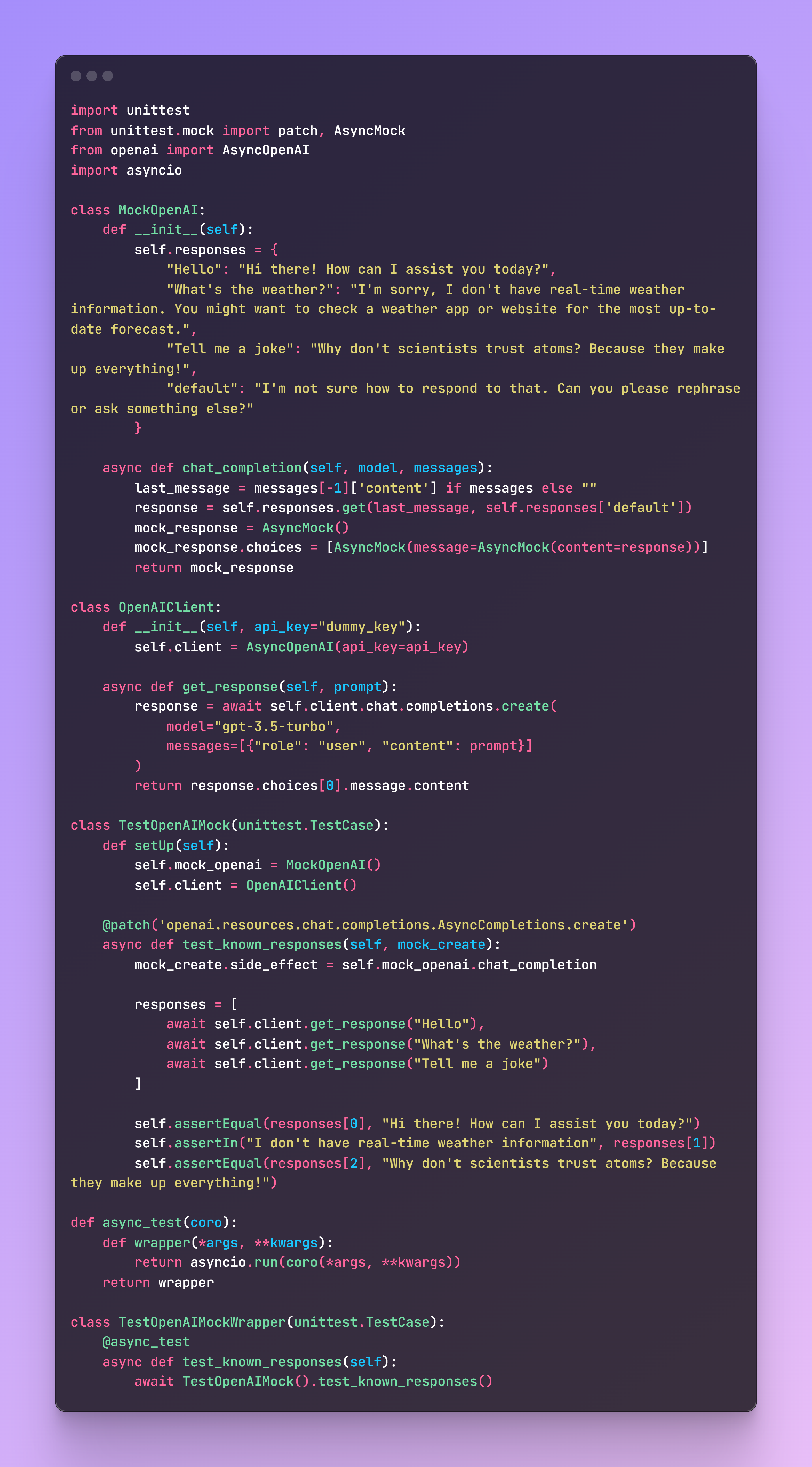
Example B. Generating Data with Faker
The faker library can be used to create dynamic and diverse data for testing. It’s not really useful for unit-test, but if you are building a mock server to facilitate development and e2e testing, this would become handy to add some randomization to your API responses. Here’s an example:
Example C. Recording Response and Mock with VCRpy
If you don’t know exact API response but still want to mock API response to add some stability to tests, VCR.py can record real API calls and replay them during tests, ensuring consistent and accurate testing. Here’s an example:
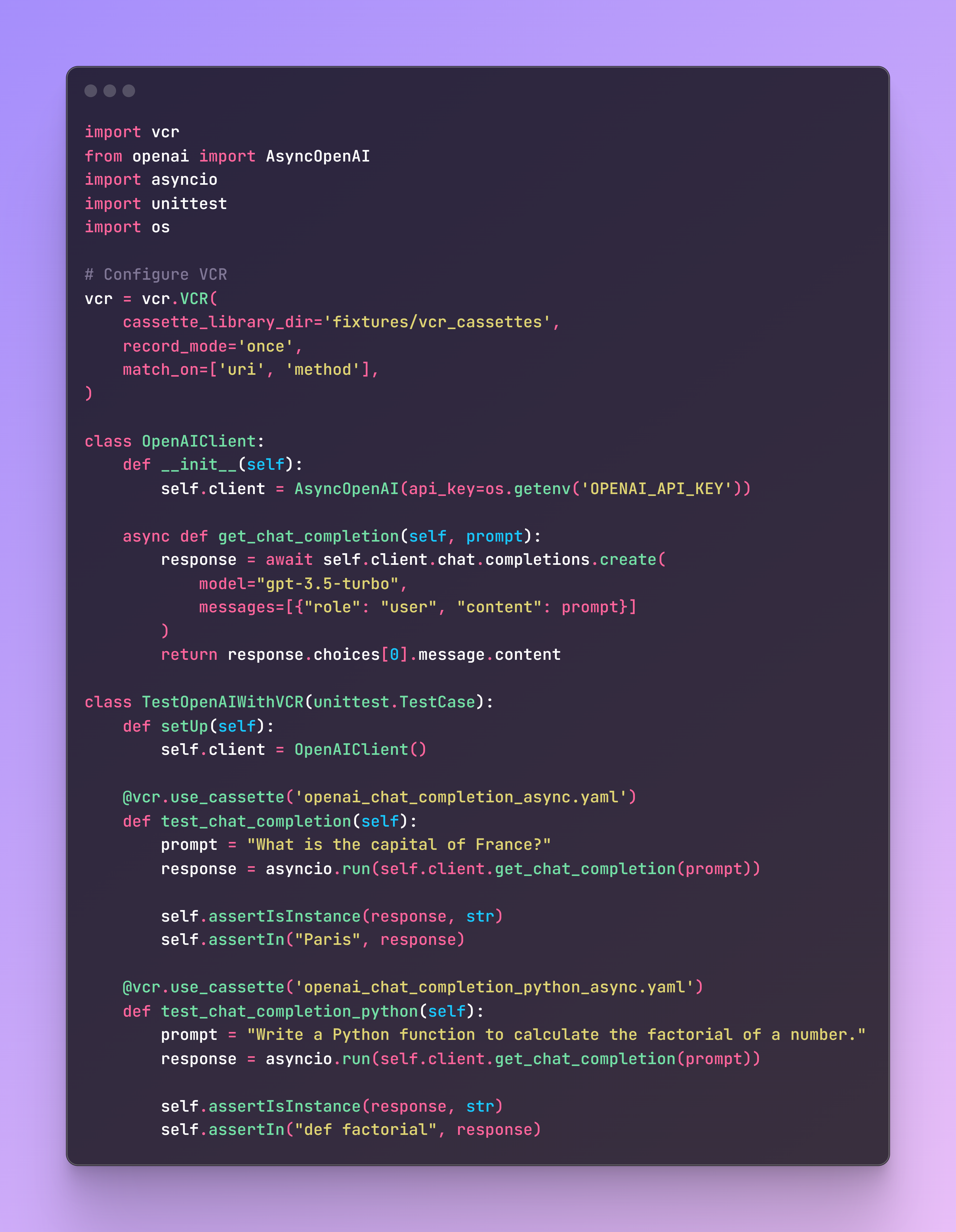
By using fixed responses, dynamic data generation with faker, or recording real API interactions with VCR.py, you can create robust mock data that ensures comprehensive testing and validation of your application.
3. Mock with testing framework and without framework
Testing frameworks like Pytest offer built-in support for mocking, making it straightforward to patch function calls and utilize mock data. This simplifies the process of testing individual components. In other cases, you might prefer to use framework-agnostic libraries, such as wrapt , to create mock servers that support end-to-end (E2E) testing. Here are two examples demonstrating how to patch the OpenAI chat completion call, one using Pytest and the other using the wrapt library.
Case A: Using Testing Framework
Pytest’s monkey patch fixture allows you to easily mock function calls for testing purposes. Below is an example of patching the OpenAI chat completion call with Pytest:
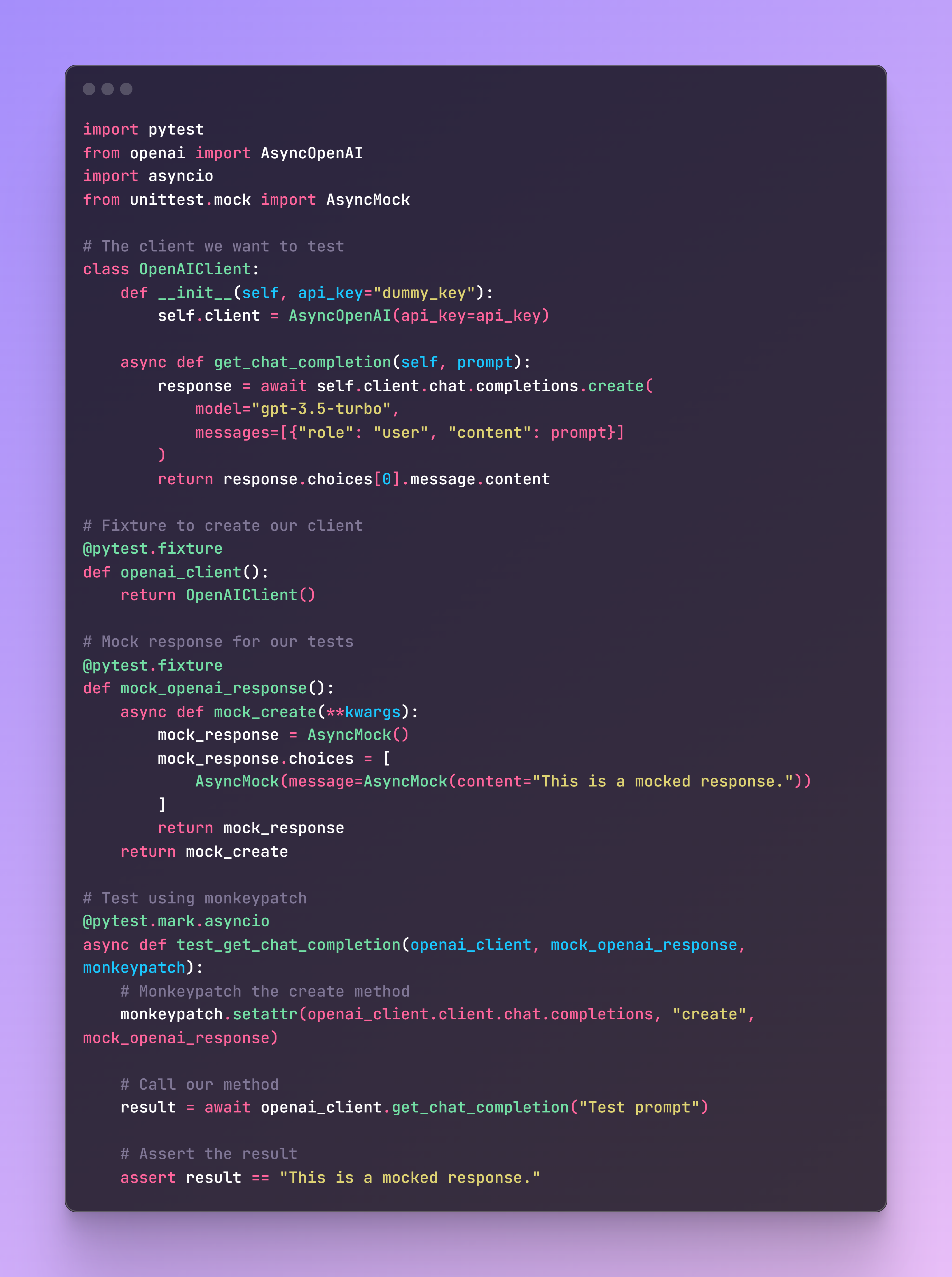
Case B: Using a Library
The wrapt library is a lightweight and flexible tool for function wrapping and mocking, suitable for use outside of specific testing frameworks. Below is an example of using wrapt to mock the OpenAI chat completion call:
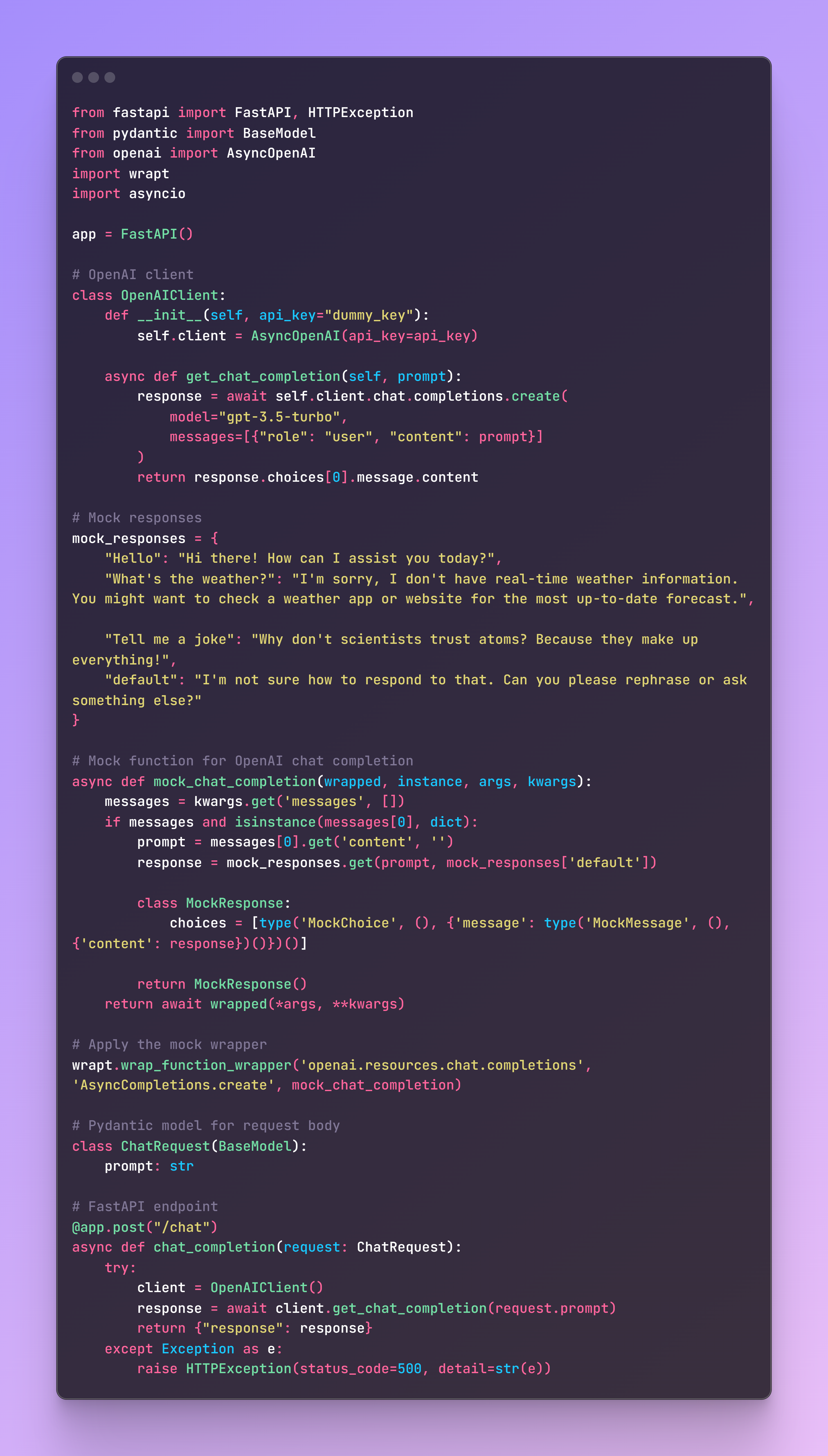
By leveraging these approaches, you can effectively mock OpenAI chat completion calls within both Pytest and a framework-agnostic context, ensuring robust and flexible testing of your applications.
4. Integrate Mocking with Test Hierarchy
Incorporating mocking into a test hierarchy ensures comprehensive and efficient testing across different levels. Here’s how mocking can be applied at various stages:
Unit Tests:
- Use mock responses to test individual functions or methods that interact with the LLM.
- Ensure that the application logic works correctly by isolating the function from external dependencies.
- Example tools: unittest, pytest with mocking.
Integration Tests:
- Verify the interaction between different components of the application by simulating LLM responses.
- Ensure that the overall system integrates correctly and handles data flow as expected.
- Example tools: pytest, responses, wrapt.
End-to-End Tests:
- Test the application in a production-like environment, but use mocking for specific scenarios that are difficult to reproduce with the actual LLM.
- Focus on the user journey and overall system functionality while controlling for LLM variability.
- Example tools: wrapt, vcrpy.
By strategically integrating mocking at these levels, you can enhance the reliability and efficiency of your testing processes, ensuring robust application performance across different scenarios.
5. And your tests can still randomly fail
The previous example demonstrated simple tests and mock usages, but real-world LLM applications often involve more complex workflows. These might include concurrent API requests or the development of autonomous agentic APIs, where mocking data can become disordered and cause test failures. To address these issues, you can employ more sophisticated data structures to store mock data or use pattern matching to ensure the correct data is returned for your tests. However, it’s essential to first consider the principles outlined in Why Shouldn’t We Mock LLM Responses when complexity escalates. Over-engineering mocks can mangle your test hierarchy, so it’s often better to explore alternative approaches to ensure robust and maintainable testing practices.
Conclusion
Effective practices for mocking LLM responses are essential for ensuring the robustness and reliability of LLM applications in production. While traditional testing methods may fall short due to the inherent complexity and unpredictability of LLMs, incorporating comprehensive unit tests, integration tests, and end-to-end tests with sophisticated mocking strategies can mitigate these challenges. Moreover, leveraging ML and LLM testing methods such as gold data benchmarks, cross-model evaluations, and probabilistic assertions provides a more accurate assessment of LLM capabilities.
By strategically integrating mocking and alternative testing approaches, development teams can maintain high productivity, control costs, and ensure robust application performance across diverse scenarios. This not only enhances the reliability of LLM applications but also facilitates efficient development cycles, ultimately leading to more successful and stable production deployments.
Originally posted at:
Dive in
Related
Blog
Competitive Differentiation for Foundation Models in the LLM Space
By Alex Irina Sandu • Dec 6th, 2023 • Views 614
Video
Why Agents are Driving Software Development to the Cloud
By Zach Lloyd • Apr 17th, 2026 • Views 54
Video
Multi-Agent Systems for the Misinformation Lifecycle // Aditya Gautam
By Aditya Gautam • Nov 25th, 2025 • Views 118
Video
Why Agents are Driving Software Development to the Cloud
By Zach Lloyd • Apr 17th, 2026 • Views 54
Video
Multi-Agent Systems for the Misinformation Lifecycle // Aditya Gautam
By Aditya Gautam • Nov 25th, 2025 • Views 118
Blog
Competitive Differentiation for Foundation Models in the LLM Space
By Alex Irina Sandu • Dec 6th, 2023 • Views 614