
Introducing the ML Kickstarter

# ML project
# ML Kickstarter
# Cheffelo
Go from 0 to 100 with ML Kickstarter
August 7, 2024
Mats Eikeland Mollestad
Setting up a new ML project for personal projects have always been a pain for me. I often find it too time-consuming to set up an end-to-end system that replicates a deployable system, while also being enjoyable to develop without breaking the bank.
Therefore, this blog post will go through how I solved this and created what I think is an incredibly elegant ML project structure.
Goals
My goals were quite hairy, as I wanted the following.
- A system that contains most of the functionality a mature end-to-end ML system has.- Built to run the codebase on your local machine- Everything should be using software development practices
But before we go into the details do I want to be a bit more concrete in the above requirements.
End-to-end system
I wanted something that makes it easy to spin up a system that replicates features you often find in a mature ML system.
More precisely this meant I wanted:1. Model experiment tracking2. A model registry3. A feature store for tabular data and embeddings4. Data validation5. Dataset versioning6. Pipeline orchestration7. Model serving8. Online model performance tracking9. A data catalog10. Data lineage through models and feature transformations11. A vector database
Run codebase locally
I wanted to avoid the need for a cloud provider for two reasons.
1. I find running my codebase locally leads to a way better developer experience, as the feedback loop is faster.2. I do not want to spend any money unless I absolutely have to.
Implementation
Before I could get started on the ML-related details, I would first need to figure out how to run my jobs in Python.
Therefore, I landed on using Docker for versioning the operating system, and any OS-related setup. Such as Python Venv setup, Python manager, etc.
NB: A Docker system would also work perfectly with a mono-repo, as the Docker images makes it easy to have different projects with conflicting requirements, while also keeping the project size fairly low.
Furthermore, I landed on using Prefect to trigger code runs. As this makes it easy to write almost pure Python methods, but still get observability, logging, alerting, scheduling, and way more.
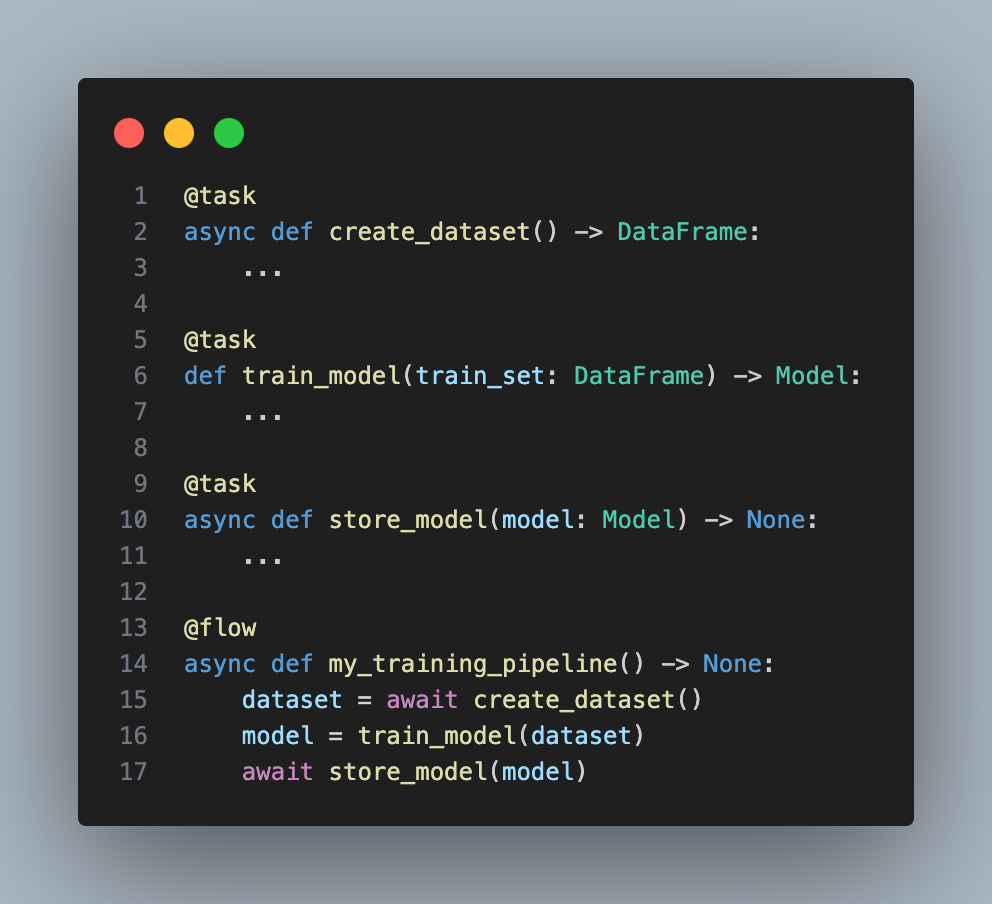
An example of a Prefect flow
Another advantage to using Prefect, which is Python first is that it reduces the amount of YAML code, meaning we can use tools such as mypy to quality control our work in a CI pipeline.
However, to get Prefect working would I also need to spin up a worker node, and a server to orchestrate work. So I leverage docker-compose to spin up all the needed infrastructure for you.
Lastly, working with Docker can be a bit painful at times, especially if you build the image on each update. Therefore, I made sure that all the source code would be updated instantly on each save by leveraging Docker volumes and watchfiles. Leading to a setup with minimal build steps, and server restarts.
Now we have a setup that can run code, so it was finally time to set up the ML-specific code.
The ML components
I started by selecting which model registry and experiment tracker to use. Where I landed on using mlflow as it is a package I was very familiar with, but also because it is widely used. However, I created a thin wrapper to make mlflow behave as I would like, while also making it easy to swap out with other packages. E.g. with streamlit, for interactive debugging.
Next up is a way to manage the data. Both in the sense of dataset creation, but also a method for providing observability on how models depend on models. For this, I ended up choosing aligned which is a declarative ML management tool, focused on the product outcome, rather than the model artifacts. And that I wrote myself, so I wanted to show how easy ML systems could be. The core idea behind aligned is that we define a model contract, which answers common questions we have about our ML system, and then aligned handles everything to connect the dots. E.g. defining the input, and output format. Where and in what format do we store the predictions? Do we store date-times as ISO or as Unix timestamps? Where and how can we use the model, and where are the related datasets stored?
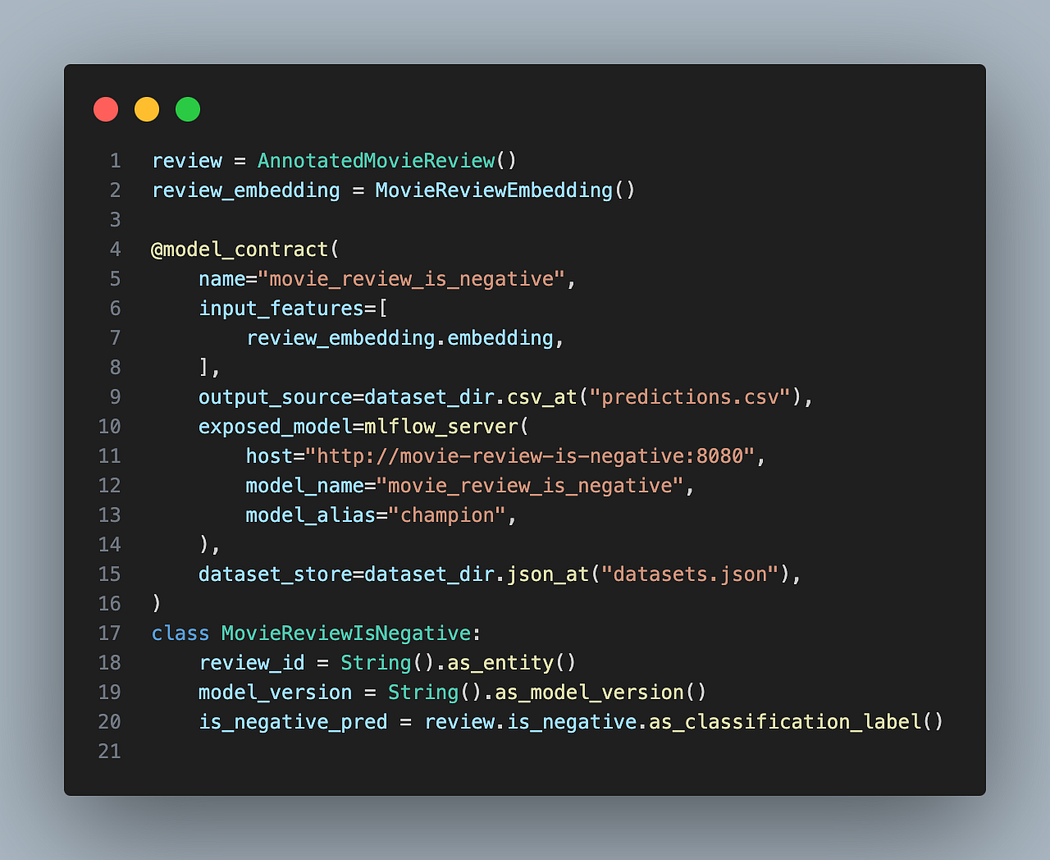
An example of an advanced model contract
Furthermore, a common component in a modern ML stack is a way to manage embeddings. Therefore, I landed on using ollama to create embeddings locally, and running LLMs if wanted. Which also saves a few more bucks.
Generating the embeddings is one thing, but storing them is another. Which meant I also added a vector database using lancedb.
Lastly, we also need to host and expose our models in some way. Thankfully mlflow have a very nice integration for model serving that enables the usage of the mlserver by seldon.
And that rounds up all the packages used in production. prefect, mlflow, aligned, streamlit, mlserver, and ollama.

Tech Stack Overview
Components
By combining the technologies described above have I managed to string a few useful components together. Some are briefly mentioned above, but I want to showcase a few specific ones.
Data Catalog
First is the data catalog which provides a simple way to get an overview over the project, but also to do some simple data management.
Furthermore, since Aligned collects information about data dependencies for both data sources and models are we able visualize their relationship as shown below? Where the rounded squares are views, and the trapezoids are ML models.
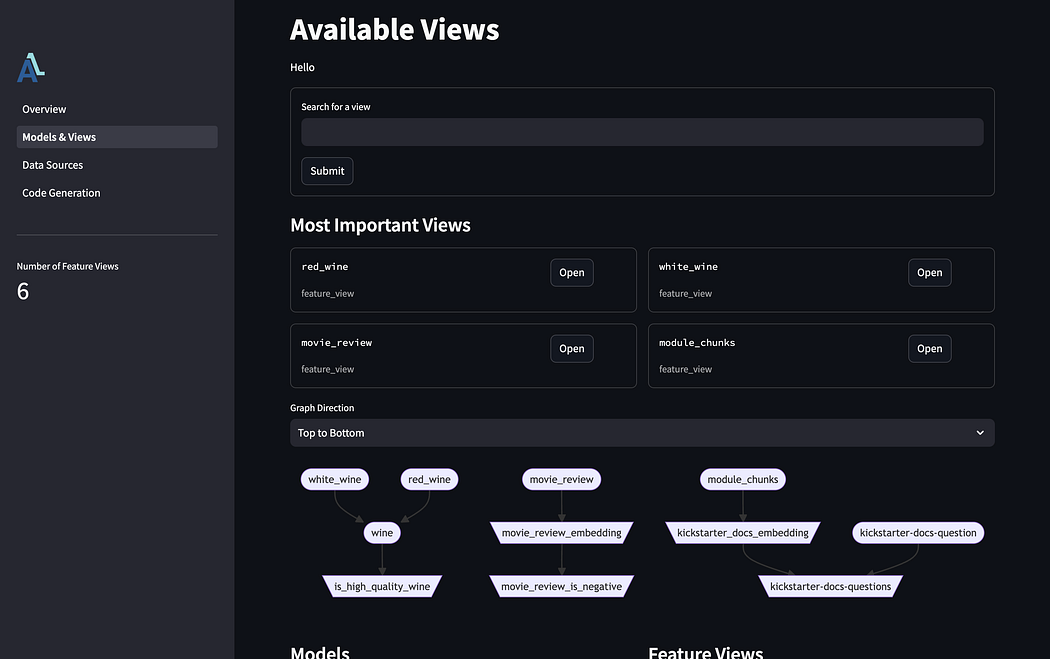
However, you can also do way more here like: Checking the health of any source, materializing data, debugging transformations, generating datasets, evaluating models, and so on.
Predefined workflows
Furthermore, there are a few common jobs that most data and ML projects need. Mainly making sure our data is up to date, but also some basic train test pipelines.
Therefore, Kickstarter comes with a built-in pipeline to incrementally update all data that is out of the defined freshness requirement. This will update all views but also predict for models that do not require any joins.
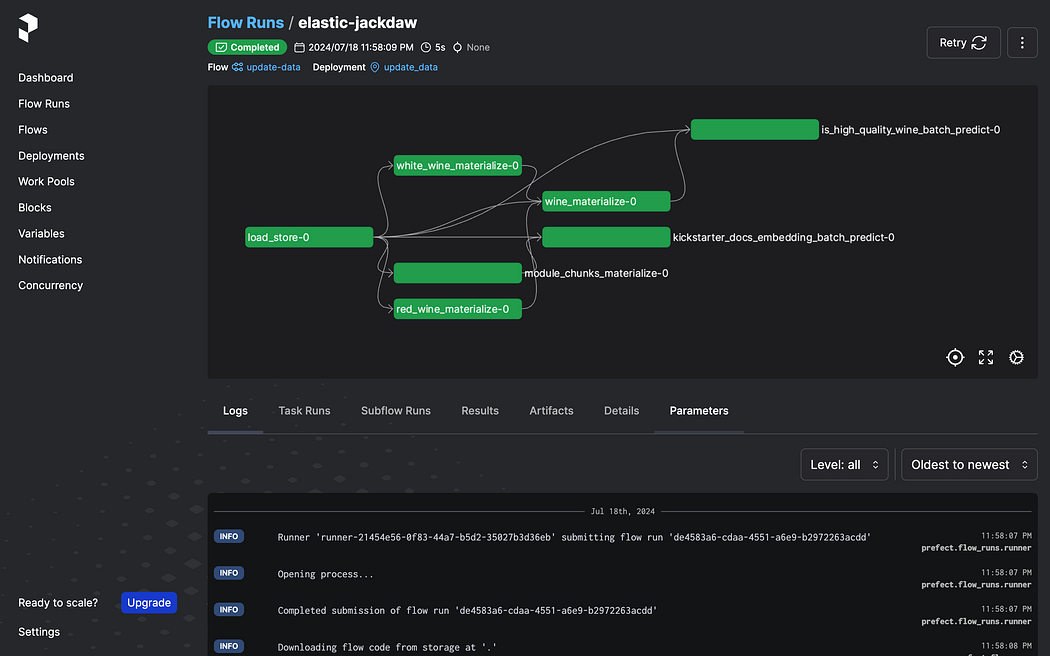
Furthermore, Kickstarter also provides a workflow that trains and evaluates a model based on the provided model contract. Meaning all you define is who to train on, and the workflow creates train and test datasets, does hyperparameter tuning, trains the model, stores the model, and evaluates the model.
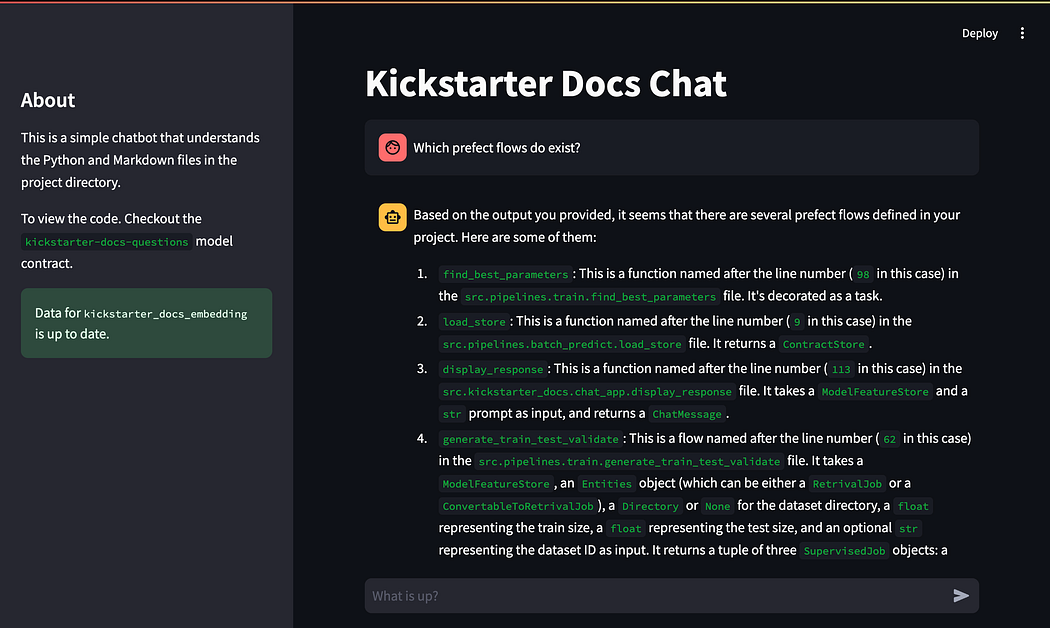
Lastly, as a slight fun addition. The Kickstarter also provides a simple chatbot that tries to answer questions about the project. As it chunks the project's Python code and read me files. This will also update its vector database every 15 minutes to make sure the context is up to date with your changes.
Conclusion
This rounds up the Kickstarter project, where it provides a setup with a good software development foundation, while also providing the core components needed for most ML and AI applications.
Check out the read-me to see how the ml-kickstarter project would be used with practical examples, at GitHub.
Dive in
Related
Video
The Future of ML and Data Platforms, The Future of ML and Data Platforms
By Michael Del Balso • Sep 29th, 2021 • Views 899
Video
The Future of ML and Data Platforms, The Future of ML and Data Platforms
By Michael Del Balso • Sep 29th, 2021 • Views 899