
ML pipelines in the age of LLMs: from local containers to cloud experiments

# LLMs
# ML Pipelines
# Cloud Experiments
End-to-end pipelines with Kubeflow, Docker, uv, Vertex AI, and Experiment Tracking on Google Cloud
January 8, 2025
Gleb Lukicov
Are you a data scientist or an AI engineer trying to bridge local development and scalable deployment of ML projects without the hassle? 🤔 As always, you are faced with the age-old dilemma — how can you move fast developing and testing new features while collaborating with your colleagues and sharing results easily? To add another complication, LLMs can add considerable costs and development time, lowering your project’s ROI if not managed correctly. How do we reconcile these challenges, you ask? ML pipelines, of course 🚀!

“To a man with a hammer, everything looks like a nail.” Well, in the MLOps world we don’t shy away from over-reliance — for a good reason — on pipelines 👷 Photo by Martti Salmi on Unsplash
To increase collaboration, all ML experiments should run off the same underlying code and data sources, eliminating the common “works on my laptop” problem 🙈. A centralised ML platform, such as Vertex AI Pipelines on Google Cloud, provides a scalable environment to run ML jobs — with MLOps best-practice features like artifact versioning, data lineage, and experiment tracking out-of-the-box. These tools are vital for tweaking input parameters and recording resultant metrics effectively (e.g. “how does accuracy change with a range of temperature values?”).
A pipeline is an effective solution to an ML task, as you can break it into isolated steps like “get data,” “call LLM,” and “evaluate results”. Each step runs as its own isolated container, linked to other steps through inputs and outputs. This design enables checkpoints and caching — key features for rapid development cycles.

A simple pipeline which retrieves some data (e.g. prompts), makes a number of calls to an LLM and evaluates its outputs.
What we have so far is a recipe for success. However, the final ask of your ML pipelines should be the ability to iterate, test, and build locally 💪. The entire experience should be available end-to-end on your laptop to shorten development cycles and get fast feedback when writing new code or creating pipelines. You want to avoid a situation where you have to wait minutes until your remote job fails due to a typo or an import error. Instead, local running can be used to ensure the whole process works locally, and then use a cloud environment to run multiple pipelines at scale and with confidence. This setup can be achieved with Docker Desktop and Kubeflow Pipelines (v2).
Local pipelines on your laptop
The end goal is to be able to trigger our pipeline with a single command:
python pipelines/demo.py --localand see an output like:
{'accuracy': 1.0}---------------------------------------------Pipeline 'demo' finished with status SUCCESSwith our simple demo pipeline looking like this (the full pipeline code is available in this demo repository):
from kfp.dsl import pipelinefrom dataclasses import dataclass
@dataclassclass JobParams: pipeline_name: str = "demo" experiment_name: str = "demo-experiment" data_source: str = "my_prompts" model_name: str = "gpt5" # 😉 enable_caching: bool = True
job_params = JobParams()
@pipeline(name=job_params.pipeline_name)def demo_pipeline(): # Step 1: Get data data_task = get_data(data_source=job_params.data_source)
# Step 2: Call LLM with the data llm_task = call_llm(model_name=job_params.model_name, prompt=data_task.output)
# Step 3: Evaluate results evaluate_results(results=llm_task.output)
from kfp.dsl import pipelinefrom dataclasses import dataclass
@dataclassclass JobParams: pipeline_name: str = "demo" experiment_name: str = "demo-experiment" data_source: str = "my_prompts" model_name: str = "gpt5" # 😉 enable_caching: bool = True
job_params = JobParams()
@pipeline(name=job_params.pipeline_name)def demo_pipeline(): # Step 1: Get data data_task = get_data(data_source=job_params.data_source)
# Step 2: Call LLM with the data llm_task = call_llm(model_name=job_params.model_name, prompt=data_task.output)
# Step 3: Evaluate results evaluate_results(results=llm_task.output)where our components (steps) are linked to each other via their inputs and outputs:
from kfp.dsl import component, Output, Metrics@component(base_image="kfp-component-local:latest")def get_data(data_source: str) -> str: import logging logging.info(f"Getting data from: {data_source}") return "data"@component(base_image="kfp-component-local:latest")def call_llm(model_name: str, prompt: str) -> str: import logging logging.info(f"Calling LLM model {model_name} with prompt: {prompt}") return "results"@component(base_image="kfp-component-local:latest")def evaluate_results(results: str, metrics_output: Output[Metrics]): metrics_output.metadata = {"accuracy": float(results == "results")}The “magic” that makes it work locally, is the kfp (Kubeflow Pipelines) local.DockerRunner() method:
from kfp import compiler, localdef compile_and_run_pipeline_locally(pipeline_func): compiler.Compiler().compile(pipeline_func=pipeline_func, package_path="pipeline.json") local.init(runner=local.DockerRunner()) pipeline_func()if __name__ == "__main__": compile_and_run_pipeline_locally(pipeline_func=demo_pipeline)We also need to have the kfp-component-local:latest container available on our system, which we prepare with this docker-compose-kfp-local.yml:
services: app: image: kfp-component-local build: dockerfile: Dockerfile target: local context: . args: - ADC restart: always...# Copy project filesCOPY uv.lock pyproject.toml README.md ./# Update the project's environmentRUN --mount=type=cache,target=/Users/$USER/Library/Caches/uv \ uv sync --frozen --no-dev --no-install-project --link-mode=copyFROM base AS local# Use staged build to only do this locally: inject user's ACCESS_TOKEN into json fileARG ADCRUN echo "$ADC" > /root/application_default_credentials.jsonENV GOOGLE_APPLICATION_CREDENTIALS=/root/application_default_credentials.json \ GOOGLE_CLOUD_PROJECT=MY_GCP_PROJECTBy using — mount=type=cache at each layer we are utilising our local Docker cache, such that subsequent builds are taking less than ~10 seconds (on Apple M3 Max) 🚀 We are also using uv to help us manage and lock our project’s dependencies effectively (think of uv as a modern and fast plug-and-play replacement for poetry).
We also have multi-stage builds, with the local stage only executing when calling this Dockerfile via our docker-compose (target: local field). We need this for injecting our user’s Application Default Credentials (ADC) JSON file into the container. When this file is available inside the container, running commands that need to authenticate with Google Cloud, will work just like running Python function locally. ⚠️ However, you should be vigilant to never push this container remotely (as it essentially has your user’s 24-hour authentication token). The way to pass ADC to Dockefile is via the — build-arg argument:
docker compose -f docker-compose-kfp-local.yml build --build-arg ADC="$(cat ~/.config/gcloud/application_default_credentials.json)"<br>So, now you have a robust way of making pipeline changes (e.g. adding a new package to your pyproject.toml or creating a new component) and running the whole pipeline (including connecting to GCP):
- Re-build the local container (if necessary) with docker compose -f ...
- Trigger the pipeline with python main.py
And see the output locally within seconds 😎

Running the pipeline locally, and seeing the final output within seconds.
Remote pipelines on Google Cloud
Now that we have a way to build, test and run our pipelines locally. When we run on Google Cloud’s Vertex AI platform, we can leverage remote cloud compute to run pipelines at scale and be able to share the results easily.
What we need now is a way to switch between local and remote pipeline execution at run time, which we can do by extending our original pipeline code to include:
def get_value_from_config(option: str, config_file: Path = Path("config.cfg")) -> str: config = configparser.ConfigParser() config.read(config_file) return config.get(section="job_constants", option=option)
@dataclassclass JobConstants: GCP_PROJECT: str = "MY_GCP_PROJECT" LOCATION: str = "europe-west2" SERVICE_ACCOUNT: str = f"pipeline-runner@{GCP_PROJECT}.iam.gserviceaccount.com" BASE_IMAGE: str = get_value_from_config(option="base_image")
job_constants = JobConstants()
@component(base_image=job_constants.BASE_IMAGE)def get_data(data_source: str) -> str: import logging logging.info(f"Getting data from: {data_source}") return "data"Where we have a JobConstants class that holds destination details (project, zone) as we all as the base image value, allowing us to define which container is being used by our components in this decorator @component(base_image=job_constants.BASE_IMAGE) via config.cfg:
[job_constants]base_image = europe-west2-docker.pkg.dev/GCP_PROJECT/MY-REPO/kfp-component:USER-latestWe can (automatically) update config.cfg before triggering the pipeline: for local execution, we set base_image to kfp-component-local:latest that has our ADC, while for remote we use kfp-component:USER-latest. We also re-use the previous Dockerfile without changes, but now using cloudbuild-vertex.yml to submit the job to Cloud Build to compile the container remotely (the full Cloud Build yaml file is available here):
... - '--build-arg' - 'BUILDKIT_INLINE_CACHE=1' - '--cache-from' - 'europe-west2-docker.pkg.dev/${_PROJECT_ID}/${_REPO_NAME}/kfp-component:${_USER}-latest' - '.' env: - 'DOCKER_BUILDKIT=1' - 'COMPOSE_DOCKER_CLI_BUILD=1'We use BuildKit and cached Docker images on Cloud Build to speed up our build 🚀 There is no need to optimise Cloud Build resources further (i.e. using non-standard VM for builds) as any increase in build performance will be wiped out by cold starts, as the whole remote build is now under one minute due to caching 🔥
def get_date_time_now() -> str: """Return current date & time, e.g. `2024-08-08--15-27-51`""" london_tz = ZoneInfo("Europe/London") return datetime.now(tz=london_tz).strftime("%Y-%m-%d--%H-%M-%S")def compile_and_run_pipeline_on_vertex(job_params: JobParams, pipeline_func): compiler.Compiler().compile(pipeline_func=pipeline_func, package_path="pipeline.json") job = aiplatform.PipelineJob( display_name=job_params.pipeline_name, template_path="pipeline.json", job_id=f"{job_params.pipeline_name}-{os.getenv('USER').lower()}-{get_date_time_now()}", enable_caching=job_params.enable_caching, location=job_constants.LOCATION, project=job_constants.GCP_PROJECT, ) job.submit(service_account=job_constants.SERVICE_ACCOUNT, experiment=job_params.experiment_name)def run_pipeline_on_vertex_or_locally(pipeline_function, job_params: JobParams, local: bool): if local: logging.info("Running the pipeline locally.") compile_and_run_pipeline_locally(pipeline_func=pipeline_function) else: logging.info(f"Running the pipeline on Vertex AI project {job_constants.GCP_PROJECT}.") compile_and_run_pipeline_on_vertex(pipeline_func=pipeline_function, job_params=job_params)if __name__ == "__main__": def main(local: bool = typer.Option(False, help="Run the pipeline locally instead of on Vertex AI")): run_pipeline_on_vertex_or_locally(pipeline_function=demo_pipeline, job_params=job_params, local=local) typer.run(main)where get_date_time_nowand os.getenv(‘USER’) allow us to add a unique timestamp and user name for each pipeline. And typer helps us to control the execution with --local argument (think of this as a modern argparse for Python).
So now, all we gotta do is:
- Re-build the remote container (if necessary) with
gcloud builds submit \ --config cloudbuild-vertex.yml \ --project MY_PROJECT \ --substitutions _PROJECT_ID=MY_PROJECT,_USER=USER \ --service-account projects/my-project/serviceAccounts/pipeline-runner@MY_PROJECT.iam.gserviceaccount.com<br>2. Run the pipeline
python pipelines/demo.py<br>And see our pipeline executed remotely on Vertex AI 🤠:
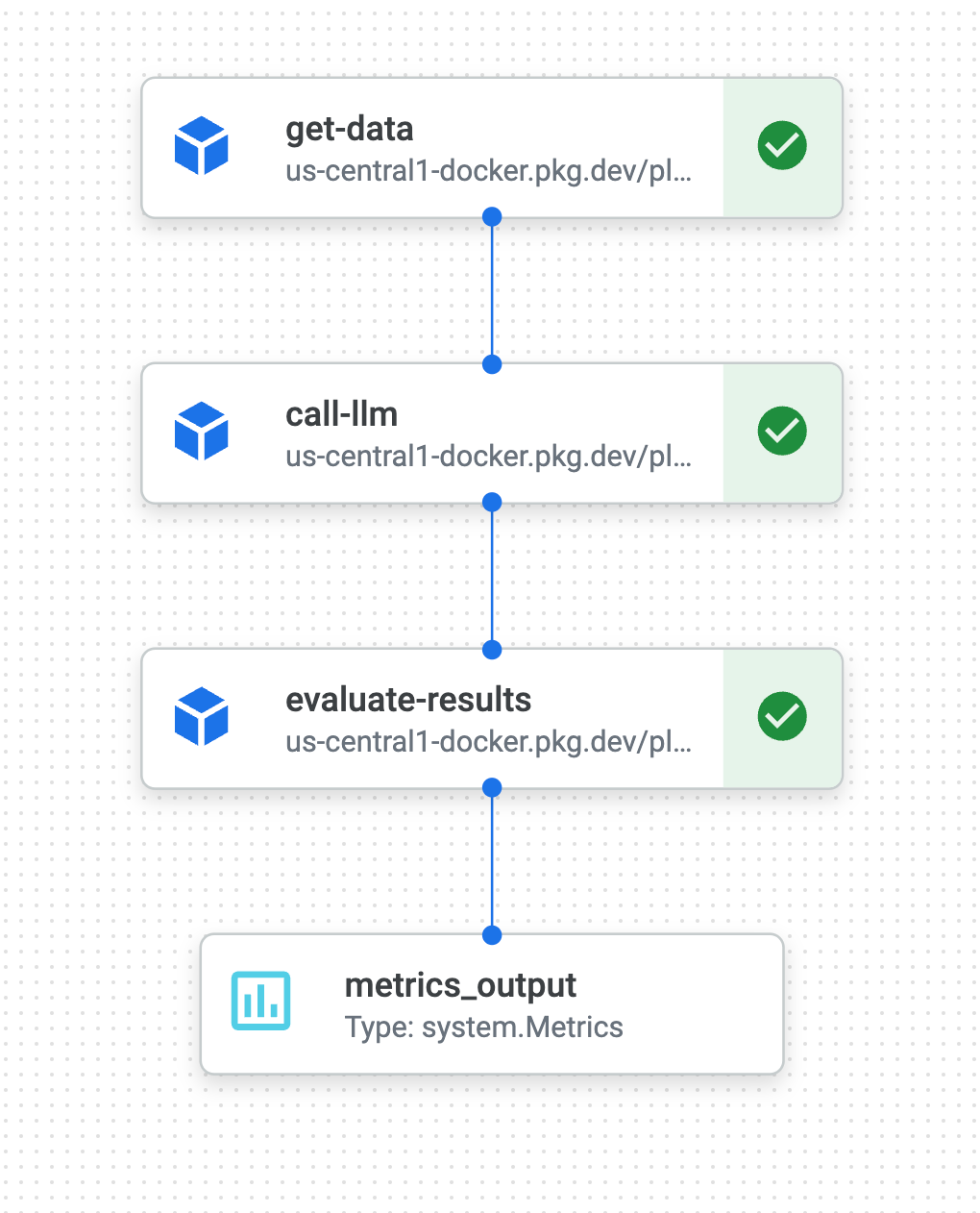
Our demo pipeline on Vertex AI.
Tracking experiments
When working with LLMs you want to build flexibly, with evaluation tools in place, to be able to switch LLM providers at will — make your systems data-centric and model-agnostic. This gives you agency to control costs and improve your accuracy. To do that, you need to compare pipeline runs as part of a larger experiment. For example, an LLM becomes a parameter and accuracy becomes the target. In fact, you can populate metrics_output.metadata with any custom metrics relevant to your experiment
@component(base_image=job_constants.BASE_IMAGE)def evaluate_results(results: str, metrics_output: Output[Metrics]): metrics_output.metadata = {"llm": "gpt5", "accuracy": 0.8}and then compare the results for multiple pipeline runs

Comparing accuracy for different models.
This way, we track all input parameters, save all intermediate artefacts, and log all metrics, greatly empowering our experimentation capability 💪.
Afterword
I hope you found this end-to-end implementation of local and remote Kubeflow pipelines with Vertex AI helpful. To make it even more accessible, I have made the full solution available as a self-contained repository 🚀 . Along with it, I have included a variety of infrastructure tools: GitHub CI/CD & pre-commit config for linting & testing, local scripts with typer , project dependency management with uv, and static checking with mypy. Have you discovered any other tools that have been game-changers in your ML journey? Feel free to share them in the comments below — I’d love to hear your thoughts! 🤝
My renewed passion for pipelines was ignited during my work at Electric Twin, where we are developing intelligence-as-a-service platforms that simulate human behaviour in real-time. This helps organisations deliver the right message to the right person, at the right time 😎 Collaborating and experimenting at scale on Google Cloud’s Vertex AI platform is pivotal in enhancing the accuracy of our engine, allowing us to provide reliable, actionable insights to our customers. For the latest updates, check out our LinkedIn page! 👋
Originally posted at:
Popular
Dive in
Related
Video
From MLOops to MLOps: LLMs & Stable Diffusion in the Cloud
By Alex Payot • Aug 7th, 2023 • Views 522
Video
MLflow Pipelines: Opinionated ML Pipelines in MLflow
By Xiangrui Meng • Aug 2nd, 2022 • Views 2.7K
Video
From Arduinos to LLMs: Exploring the Spectrum of ML
By Soham Chatterjee • Jun 20th, 2023 • Views 787
Video
From MLOops to MLOps: LLMs & Stable Diffusion in the Cloud
By Alex Payot • Aug 7th, 2023 • Views 522
Video
From Arduinos to LLMs: Exploring the Spectrum of ML
By Soham Chatterjee • Jun 20th, 2023 • Views 787
Video
MLflow Pipelines: Opinionated ML Pipelines in MLflow
By Xiangrui Meng • Aug 2nd, 2022 • Views 2.7K