
Scaling ML Model Development With MLflow

Model prototyping and experimenting are crucial parts of the model development journey, where signals are extracted from data and new codes are created
December 19, 2022
Demetrios Brinkmann

Demetrios Brinkmann
Model prototyping and experimenting are crucial parts of the model development journey, where signals are extracted from data and new codes are created. To keep track of all of the chaos within this phase MLflow comes to help us. In this blog post will see a possible Python SDK implementation to help your data science team to keep track of all the model’s experiments, saving from codes to artifacts to plots and related files. In this article, let’s see how your data science team 👩💻👨💻 could enjoy experimenting 🧪 with new models with an MLflow SDK. If you’re interested in MLflow and you want to go the extra mile, follow me ✋
What is MLflow?
MLflow is an open-source platform for machine learning that covers the entire ML-model cycle, from development to production and retirement. MLflow comes directly from Databricks, it works with any library, language, and framework and it can run on the cloud and it is a pivotal product for collaboration across teams.
We can define four MLflow products:
- MLflow Tracking : this component covers the model experiment phase. Data scientists can study and develop different data and models’ parameters, gather all the relevant info in MLflow and choose which model could get to the production phase
- MLflow Projects : it often happens in a big collaboration that data, APIs, and code need to be shared. Constantly collaborators come across installation issues, problems in the model, code segmentation faults, and other similar “life-threatening” hurdles. Projects allow a common format for packaging data code, making them more reproducible and sharing across teams without heart attacks
- MLflow Models : once a team lands on the production land, the next step is to avoid confusion and mess of models. Models allow deploying machine learning models in diverse environments in an easy and intuitive way
- MLflow Model Registry : and how to avoid the final mess in production? A registry is a solution, keeping track of all the model’s status, whether they are in production, in staging or they are finally retired.
I will write 3 articles about MLflow, which will deal with MLflow Tracking and MLflow models. In particular, in this story, I’ll show you how to help your team by thinking of an MLflow SDK, so that data scientists can skip some tedious parts in coding MLflow. In the second story, we’ll extend the SDK to retrieve metrics and create intuitive Plotly plots for data scientists, along with some examples. Finally, I will show you how to create an MLflow plugin, that can be used for deploying the model in GCP AI-platform
Ten seconds introduction to the MLflow environment
MLflow developers have put together this fantastic and thorough guide, to allow everyone to install MLflow and start working with it: https://mlflow.org/docs/latest/quickstart.html
Here I am going to give you a very quick glimpse, running on a local machine. After MLflow has been installed, we can write a wee code like this one:
Fig.1: A wee introduction code to MLflow
Execute this code, by running python name_of_your_file.py , and this will start a recording process in MLflow. Here is where MLflow comes into action! In your CLI just type mlflow ui to initiate the MLflow graphical interface. Head to http://localhost:5000 (or http://127.0.0.1:5000) and you’ll land in the MLflow UI (fig.2):
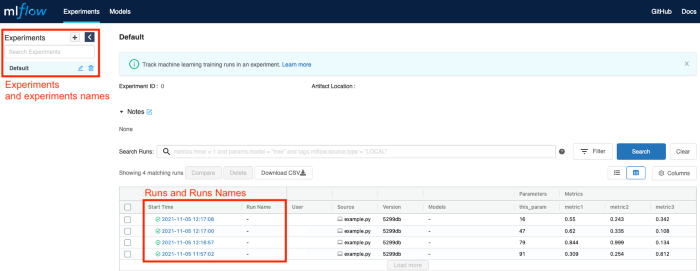
Fig.2: MLflow UI. On the left is the list of experiments and in the center the runs along with basic information and parameters, and metrics.
If you click on a specific run you’ll get a new window, as shown in fig.3. Here you can retrieve the run’s parameters (e.g. this could be the number of layers, batch size, initial learning rate, and so on), the run’s metrics as interactive plots (e.g. accuracy as a function of steps/epochs) and all the saved artifacts
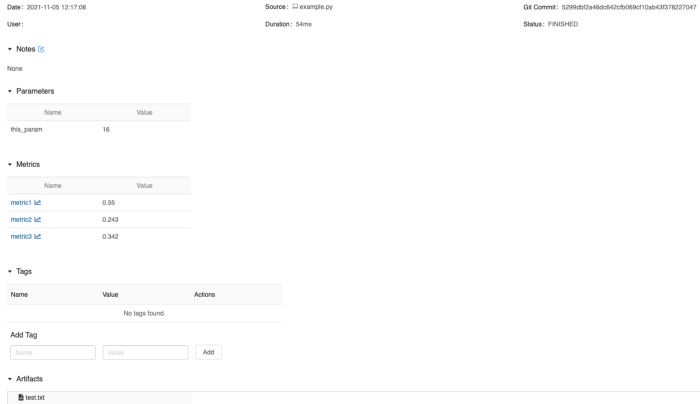
Fig.3: MLflow single run UI. In this window you can get more details about the code run and check artifacts as well
Help out your team: towards an MLflow SDK
So far so good, but now it’s time to scale up and help your data science team to integrate MLflow into their already existent models. An MLflow SDK, built on top of the MLflow package, will be a perfect solution, in order not only to lower the headache for the team to digest a new technology but also to accommodate data scientists’ requests in a simple Python class.
First thing, we need to understand what our MLflow class should do and what path we’d like to go for. Fig.4 shows a possible roadmap, from the creation of the MLflow SDK towards CI/CD and deployment through MLflow plugins

Fig.4: Roadmap sketch. The MLflow SDK should take care of existing data scientists’ models and save artifacts. Then an MLflow deployment plugin could push final results to production
Implement the MLflow tracking SDK class
Thus, the very first step is to devise a class for implementing MLflow, that could have the following functions:
- read_params this function reads the tracking input parameters, which are needed to set up a new MLflow experiment
- set_tracking_uri and get_tracking_uri: these functions set mlflow tracking uri (mlflow.set_tracking_uri) and return the current tracking uri respectively
- set_experiment_id and get_experiment_id: the set function checks whether an experiment_name has been given, otherwise it creates a new one.
- run_training: this is the main function to capture the model’s parameters and metrics (mainly through the use of the Python module inspect). Model’s parameters and metrics are retrieved automatically by mlflow with mlflow.package.autolog functions.
log_any_model_file: it happens sometimes that MLflow autolog functionalities are not able to upload saved models files to MLflow-server. This function helps data scientists in these situations. As a matter of fact, once the training has been finished, this function is called and it is able to find for all the .joblib, .h5, .pkl, .model files within the working running directory as well
- as metrics in png format and json metadata file and report them correctly to MLflow-server.
Object constructor
So let’s now start to code this up, setting up a class interface and protocol and its constructor. It could be useful to have a cloud storage option, so you can import this (e.g. fromyour_cloud_providerimportstorage_module ) and save artifacts directly on the cloud.
Fig.5: Set up the MLflow SDK interface and protocol. The SDK will live on this main object
Read input parameters
Next, we can start thinking of parsing and reading the parameters. Data scientists could parse a yaml or json or txt input files with given instructions and parameters to a Python dictionary, that could be read directly by the class:
Fig.6: Read parameters function. Data scientists could parse an input file to a dictionary, which provides instructions such as the tracking uri (e.g. http://localhost:5000), as well as the storage location, run name, and tags
Here in this example, I added self.caller. We’ll see later how this info is passed to the SDK, but this variable aims to record which script has called the MLflow SDK, to copy that Python script to the artifacts and achieve a code-lineage as well.
Code lineage is useful at run time, as many modifications can happen and, although data scientists could keep track of changes in Github, some changes may be missing, leading to puzzling and mysterious results.
Setters and getters
Following, we need to take care of the setters and getters (fig.7). These functions may sound useless, but they are so important when executing massive and long codes, that could save your life!
Fig.7: Setters and getters for the main class.
It’s worth spending a few seconds on the set_experiment_id To create a new experiment the experiment_name and tracking_storage are passed to mlflow.create_experiment(experiment_name, tracking_bucket) and from there the experiment_id is retrieved. The experiment_id, along with the run_name, is mandatory to start a new run in MLflow, thus we need to pay special attention to these variables.
Training model routine
At this point we’re ready to deal with the training routine. Usually, MLflow keeps track of model training jobs through a context manager, which is a Python protocol, that often simplifies some resource management patterns:
Fig.8: Example from the MLflow tutorial ( https://www.mlflow.org/docs/latest/tutorials-and-examples/tutorial.html ) about training tracking
The problem of context manager is that with mlflow.start_run() can record artifacts and training sessions only if directly called within the training Python code. This may be a very boring restructuring task for data scientists, who should re-write part of their codes to accommodate these functionalities. A wanted solution would be something similar:
run_training function is supposed to deal with this trick, it can listen to what the user is doing, without interfering with already written pieces of codes:
Fig.9: Main training function, that can be called to record all the model artifacts
The function calls mlflow.autlog() functions, which provide fantastic support in listening to xgboost , sklearn , tensorflow , keras, and lightgbm modules, automatically reporting all the model parameters to the main UI. The core of the function is mlflow.start_run()which sets up the run to be recorded and, as I said above, it reports the caller Python script self.caller to the artifacts folder code as mlflow.log_artifact(self.caller, artifact_path=’code’)
Log any model file/artifacts to a MLflow
One of the problems in avoiding the context manager is that not all the generated model files will be automatically saved to the MLflow server. In my case, for example, many of the model files were saved either locally or to the cloud, but I wanted them to be reported in the MLflow server as well. To patch this issue, log_any_model_file , fig. 10, comes into play.
The function calls the newly run experiments. It checks whether the experiment’s runs went fine with client.search_runs(…).to_dictionary() . Then, it looks at a given storage location, either local or cloud, to see which files have been saved and created there. Following, a list of wanted formats is scanned, local_file_to_upload , and run a for-loop to log all the found files in a model folder with client.log_artifact(run_id, file_to_upload, artifact_path=’model’)
Fig.10: log any metadata and model file to MLflow server. Sometimes not all the files are directly saved by MLflow, especially when using a mixed model. Thus, this function looks for additional artifacts on the cloud or locally and upload them to the MLflow server.
Patch all together in a module
Now that you’ve created the basis of MLflow SDK, we can go ahead with implementing a training module that data scientists could use for their experiment. The module name could be experiment_tracking_training.py which implements the functions start_training_job and end_training_job .
The former function sets up the MLflow tracking job. It retrieves the caller Python script code through a traceback module with caller = traceback.extract_stack()[-2][0] , which will be reported amongst the artifacts. Then, it initializes the experiment parameters and finally kicks off the training run runner.run_training()
end_training_job can be called after the model fitting, to retrieve any other possible file which was not saved, through the log_any_model_file().
Fig.11: Module to start and complete a training job session recording with MLflow. The start_training_job initializes the ExperimentTrackingProtocol while end_training_job checks for further artifacts which have not been saved to the MLflow server.
That’s all for today! We went through a lot of things and if you’re not familiar with MLflow you’d like to digest everything step by step. Stay tuned for our next story, which will show how to report additional metrics to our experiments and we’ll see some examples of how to use our MLflow SDK 🙂
If you have any questions or curiosity, just write me an email at stefanobosisio1 [at] gmail.com
Author’s Bio: Stefano is a Machine Learning Engineer at Trustpilot, based in Edinburgh. Stefano helps data science teams to have a smooth journey from model prototyping to model deployment. Stefano’s background is Biomedical Engineering (Polytechnic of Milan) and a Ph.D in Computational Chemistry (University of Edinburgh).
Dive in
Related
Video
MLflow Pipelines: Opinionated ML Pipelines in MLflow
By Xiangrui Meng • Aug 2nd, 2022 • Views 2.7K
Video
How Aurora Accelerates Autonomous Vehicle ML Model Development Using Kubeflow
By Ankit Aggarwal • Jan 27th, 2023 • Views 908
Video
Driving Evaluation-Driven Development with MLflow 3.0 // Yuki Watanabe // Agents in Production 2025
By Yuki Watanabe • Jul 23rd, 2025 • Views 290
Video
MLflow Pipelines: Opinionated ML Pipelines in MLflow
By Xiangrui Meng • Aug 2nd, 2022 • Views 2.7K
Video
How Aurora Accelerates Autonomous Vehicle ML Model Development Using Kubeflow
By Ankit Aggarwal • Jan 27th, 2023 • Views 908
Video
Driving Evaluation-Driven Development with MLflow 3.0 // Yuki Watanabe // Agents in Production 2025
By Yuki Watanabe • Jul 23rd, 2025 • Views 290