
Bridging the (Analytics) Culinary Gap - Part 3

# Dataplex
# Metadata
# AI
Keeping Your Data Kitchen Organized with Dataplex
March 12, 2025
Jessica Michelle Rudd, PhD, MPH
One Big Thing: Bridging the (Analytics) Culinary Gap (Part 3)

Dataplex: Your Pantry Organizer
With our recipes crafted in Dataform and our sous chef Composer/Airflow orchestrating the cooking, we need a way to keep our data kitchen organized and efficient. That's where Dataplex comes in – our pantry organizer extraordinaire!
Why Dataplex is Essential for a Tidy Kitchen
Imagine a pantry where ingredients are scattered haphazardly, labels are missing, and expiration dates are a mystery. Chaos reigns! Dataplex brings order to our data pantry, ensuring our ingredients are fresh, easily accessible, and well-documented.
Here's how Dataplex keeps our data kitchen running smoothly:
- Ingredient Inventory: Dataplex provides a clear inventory of all our data assets, much like a well-organized pantry. We can easily discover and access the data we need, whether it's raw ingredients or prepped dishes. No more rummaging through cluttered shelves!
- Freshness Guarantee: Dataplex helps us track data lineage and freshness, ensuring we're always using the most up-to-date ingredients. It's like having a built-in expiration date checker for our data, preventing us from serving stale insights.
- Recipe Documentation: Dataplex allows us to document our data assets with rich metadata, like nutritional labels for our ingredients. We can record details such as data origin, quality checks, and transformation processes. This ensures transparency and traceability in our data cooking.
Dataplex in Action: A Well-Organized Pantry
Let's see how Dataplex keeps our data kitchen tidy. Imagine we have a variety of data sources – customer orders, sales transactions, and marketing campaigns. Dataplex helps us organize these ingredients into logical shelves, making it easy to find what we need.
Setting up your pantry with Dataplex
- Create a Lake: Start by creating a Dataplex "lake." This is the main container for your data, like the pantry itself. Give it a descriptive name, like "Sales Data Lake."
- Organize with Zones: Next, create "zones" within your lake. These are like shelves in your pantry, separating different types of data. For our sales data, we might have zones like "Raw Sales Data," "Cleansed Sales Data," and "Sales Reports."
- Add your Assets: Now, it's time to stock your shelves! Add your data sources as "assets" to the appropriate zones. This could be your BigQuery tables with raw sales data, your Dataform project containing the transformation recipes, and even the final dashboards where your insights will be served.
Navigating your pantry
Once you have your assets organized, Dataplex provides a clear view of your data landscape.
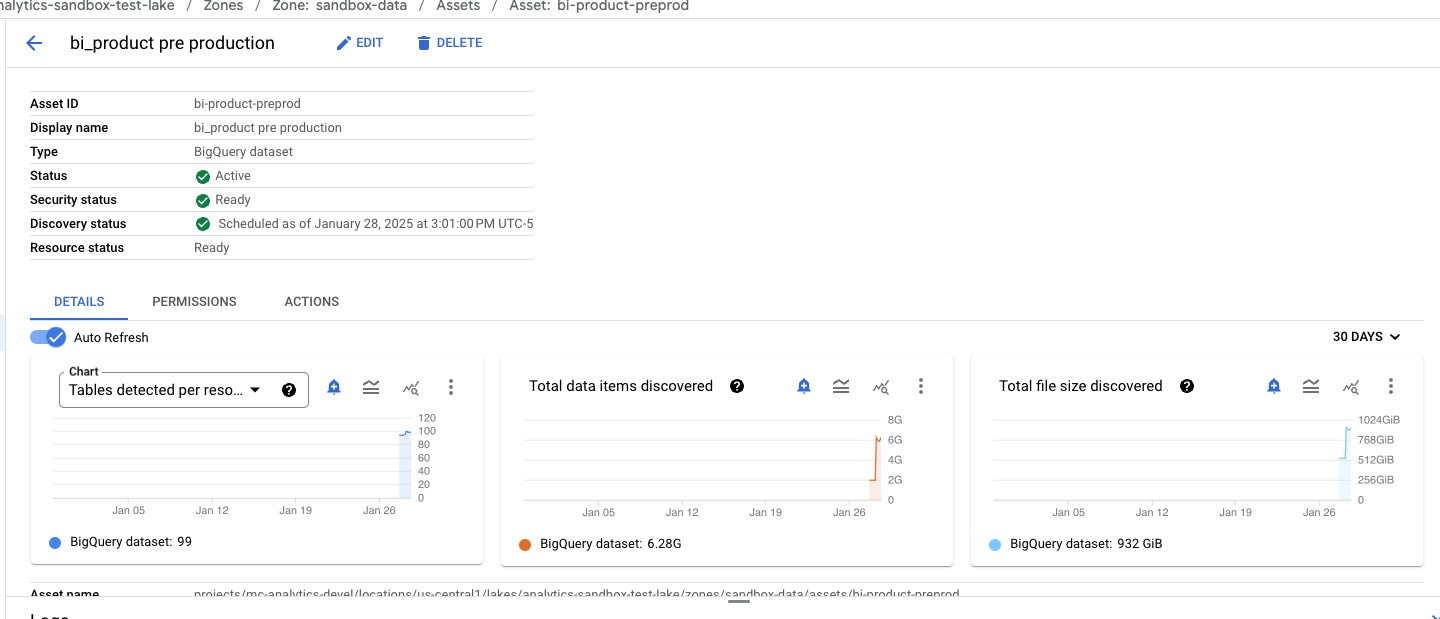
In this screenshot, we see how Dataplex automatically discovers the number of tables and total data size of our the assets in our lake. In Dataplex Discover (search) we can easily navigate through our data pantry, finding the specific ingredients (tables) we need for our ETL recipes.
Dataplex also provides detailed metadata for each asset, like a comprehensive nutritional label.
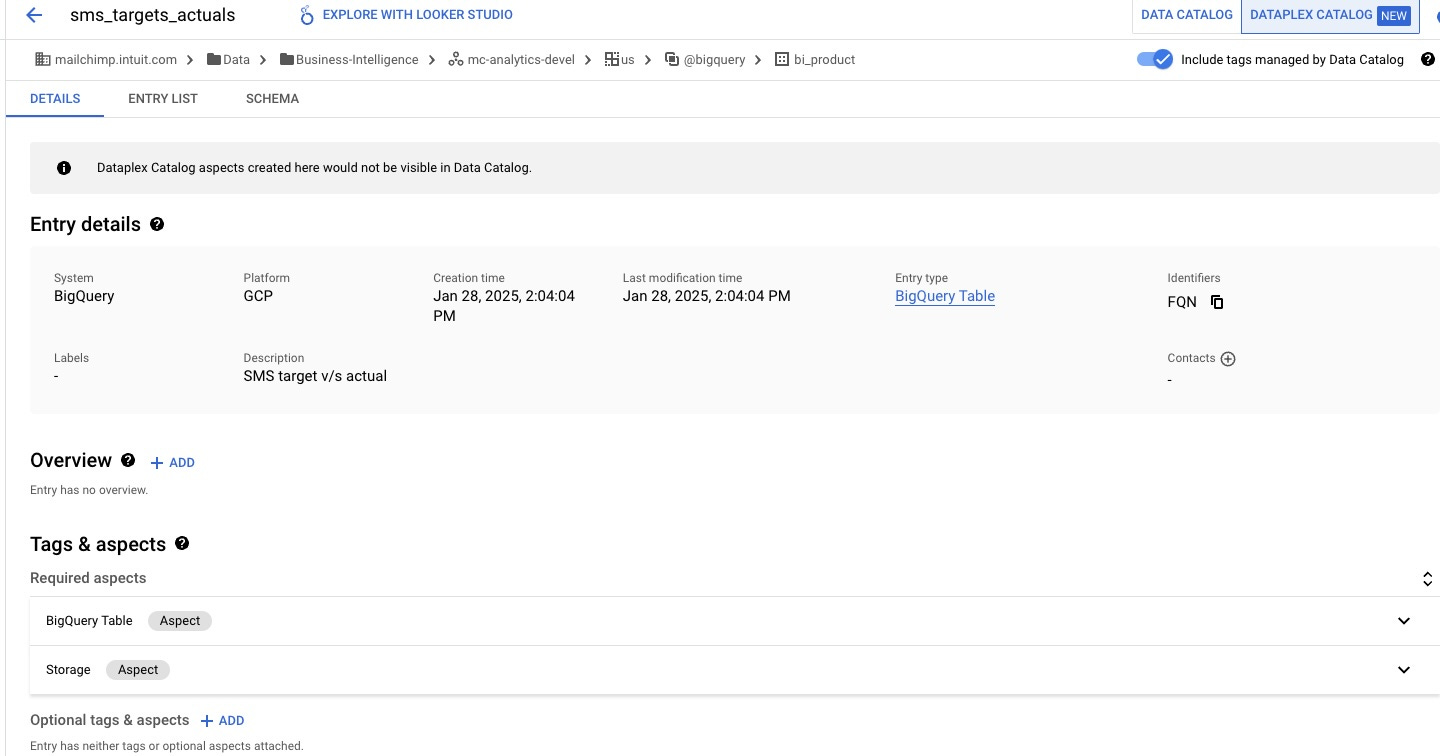
This metadata helps us understand the origin, quality, and transformation history of our data, ensuring we're using the freshest and most reliable ingredients in our recipes.
With Dataplex as our pantry organizer, our data kitchen is a model of efficiency and order. We can easily find, understand, and manage our data assets, ensuring our ETL pipeline delivers delicious insights to our stakeholders.
Helpful Resources
🍬 Sweet & Sour Candy (this week’s good, bad, or weird of the tech world)
🤢 Mark Zuckerberg gave Meta's Llama team the OK to train on copyrighted works, filing claims | TechCrunch - Plaintiffs in a copyright lawsuit against Meta allege that CEO Mark Zuckerberg approved the use of a known pirated dataset, LibGen, to train the company's Llama AI models, despite internal concerns about copyright infringement. Meta is accused of stripping copyright information from the data and using torrenting to access and distribute the pirated works, further concealing their alleged infringement.
😀 A foundation model of transcription across human cell types - Nature - Researchers have developed a new model called GET (general expression transformer) that accurately predicts gene expression across 213 human cell types using only chromatin accessibility data and sequence information. GET's adaptability across different sequencing platforms and assays enables the discovery of universal and cell-type-specific transcription factor interaction networks and facilitates regulatory inference across a broad range of cell types and conditions.
🍫 One last bite
"You will do foolish things, but do them with enthusiasm." ~Sidonie-Gabrielle Colette
Thank you for reading. This post is public, so feel free to share it.
Originally posted at:
Dive in
Related
Blog
MLOps Coding Skills: Bridging the Gap Between Specs and Agents
By Médéric Hurier • Mar 3rd, 2026 • Views 279
Blog
MLOps Coding Skills: Bridging the Gap Between Specs and Agents
By Médéric Hurier • Mar 3rd, 2026 • Views 279