
Semantic Search to Glean Valuable Insights from Podcast- Part 3

# Semantic Search
# Podcast
# OpenAI
Chatting with Podcast Data, Post-Episode
July 29, 2024
Sonam Gupta
By the time I reached my fifth podcast episode, my curiosity was piqued, I wanted to correlate what I'd learned, revisit ideas from earlier episodes, and effortlessly share summaries. That’s why in this third post of our semantic search series, I'm guiding you through the art of querying podcast transcripts for quick information retrieval. Let’s take a quick stroll down memory lane:
- In the first post , we mastered the art of transcribing podcast audio into text using OpenAI's Whisper model, storing our trove of data neatly in ApertureData’s ApertureDB for basic querying.
- Building on that foundation in the second post , we leveled up by embedding transcript chunks with LangChain’s token text splitter and Cohere’s embed-v3. These insights, along with podcast metadata, found their home in ApertureDB.
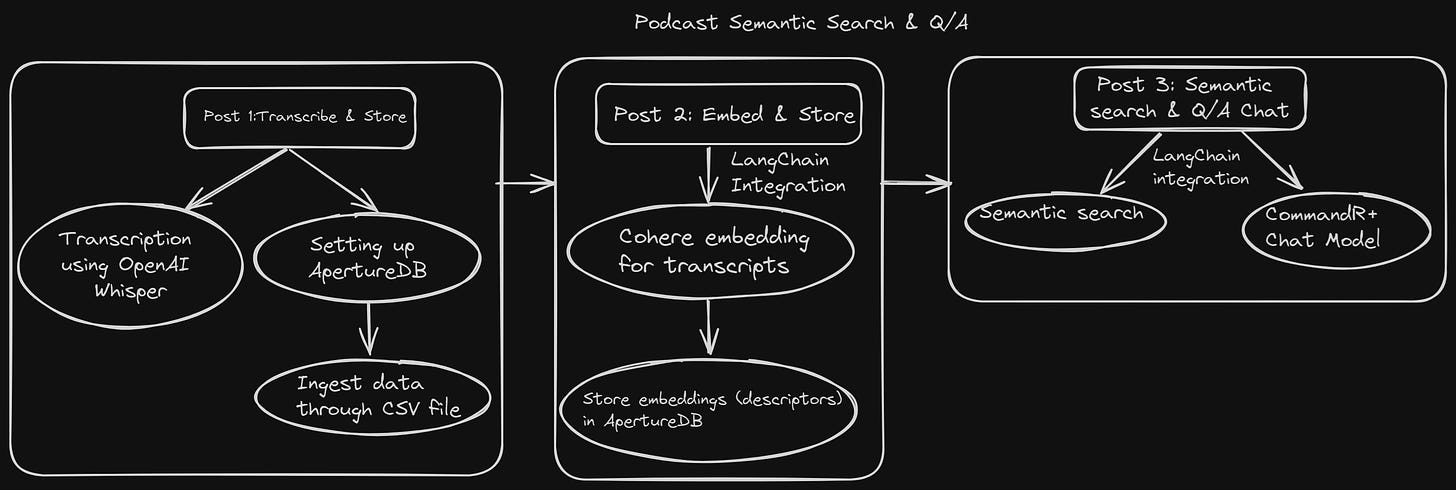
Visual Recap of the Series
The key concepts and tools used in this post are as follows:
Semantic Search
Overview of Semantic Search
Semantic search is a technique that finds the most contextually relevant answer to your query based on the content you provide. It is a significant enhancement over basic keyword-based search, which may or may not return relevant information. To get more technical details about how this technique works, check out SingleStore’s blog on the topic. This blog delves deep into how the different modules in a semantic search engine work together and why it is important. Semantic search is used in various applications, including content management systems, e-commerce platforms, internal corporate chatbots, and more.
Semantic Search in ApertureDB
The whole idea of semantic search is to find answers that are closest to the user's query in terms of context and semantics. In ApertureDB, the method “find_similar”, which is a Python wrapper for the Descriptors (embeddings) API, enables the user to find similar items (answers in our case) to the provided query. If you recall, in the 2nd post of this blog series, I defined a descriptor set (imagine a collection in other vector databases like Milvus or Qdrant) as follows [for detailed description, check out the 2 nd post ]:

Now all we have to do is to call the find_similar method and pass the descriptor set name, the number of similar answers you want (k_neighbors), distance metric , the properties you want to return, and other such parameters. For more details on this method, check out the ApertureDB documentation . Here’s how I experimented with this method:
- The first step is to initialize your embedding model API. Note, that the embedding model to embed the user query should be the same as the one you used to embed the data. In this case, I used Cohere’s embed-v3. After passing the query, I called the LangChain’s integration of Cohere embed function, to embed my query as:

- After embedding the user query, initialize the ApertureDB vector store from LangChain and pass the embedding, text, and the descriptor set as:

- Then call similarity_search() where you pass the user query and the number of top similar results you want.

- To see the output, all you have to do is:

The output looks as follows:
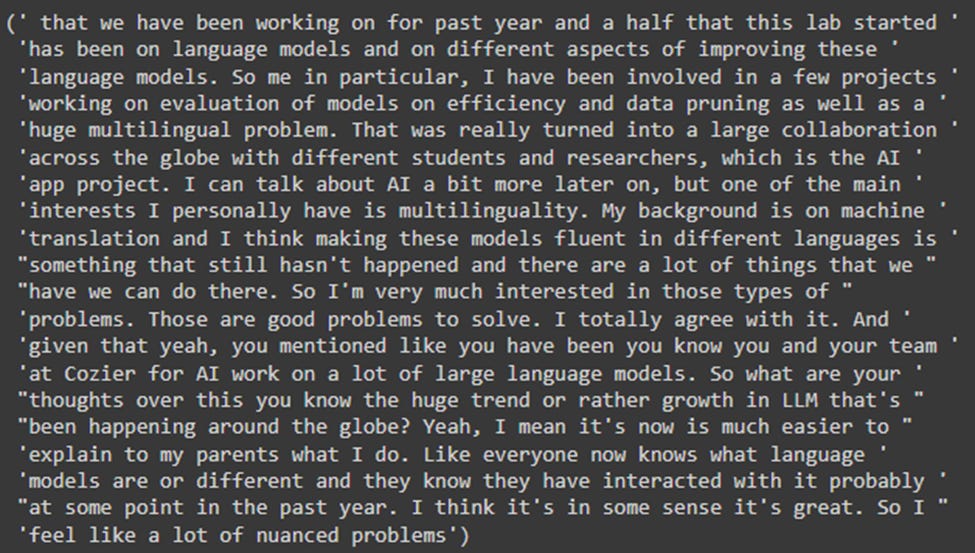
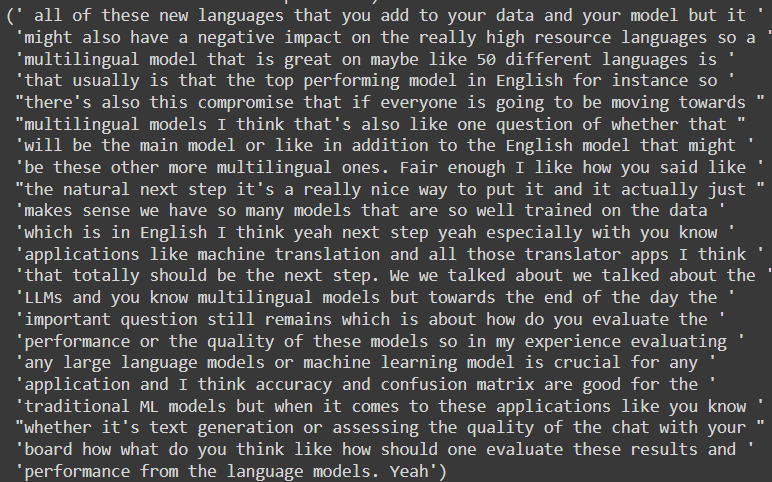
Given that there was at least one guest who spoke about multilingual AI, the semantic search model was able to find the top two relevant answers to the query, “Can you share some thoughts about multilingual AI?” I remember Marzieh mentioning how building multilingual AI models is the natural next step from our conversation . She had great insights to offer about this topic.
You can experiment with this module with a variety of questions, but keep in mind that the relevance of answers will depend on the information available in the data you provide as context for the search. In the results, you will notice some repeated information, which could be due to the limited amount of podcast data on multilingual AI or how the data was chunked. This is open for discussion. (Feel free to leave any suggestions in the comments.)
Chat with Podcast Data
Semantic search is just one possible use case once you set this up. You can now try your hands at building a question-answer style chatbot on your data. So how does one build a chat assistant for the given data? It’s simple,
- Create a retriever model for information retrieval where you pass what type of search you want the model to perform (search_type), the number of results to return (k), and the number of documents to pass to the search type algorithm.

In this snippet, I created a retriever based on the vector store (ApertureDB) initialized earlier and I passed search_type to be Maximal Marginal Relevance (MMR) that helps return results with reduced redundancy while maintaining the relevancy between the query and results. This retriever is a class from LangChain, so for more details about this module, please check out this documentation .
2. Next, initiate the LLM you want to use for chat. In this case, I used Cohere’s Command R model . This model is a strong choice for creating a chat assistant due to its ability to understand the intent behind messages, remember conversation history, and navigate through multi-turn conversations. The newer versions of this model have improved speed and provide citations for the answers it generates. The model comes with RAG enabled, a longer context window, reduced price on the hosted API, and many other features. For the chat module, I continued to use the LangChain Cohere integration as follows:

3. Once you have initialized the retriever and chat model, the next step is to set up the prompt chain. LangChain offers various modules to help you build a prompt chain for creating a chat assistant. For the chain, you need a prompt template (which includes the question and context), a chat model you want to use, and a chain to bring these together. The Runnable Protocol from LangChain lets you create a customized chain where you pass the context, which is the retriever, and the query can be parsed through RunnablePassThrough(). There are many ways to create a prompt template and the chain, but this technique is easy to use:

4. The last step is to invoke the chain where you can pass the question you want to ask the assistant followed by the answer in its raw output format:

Answer:


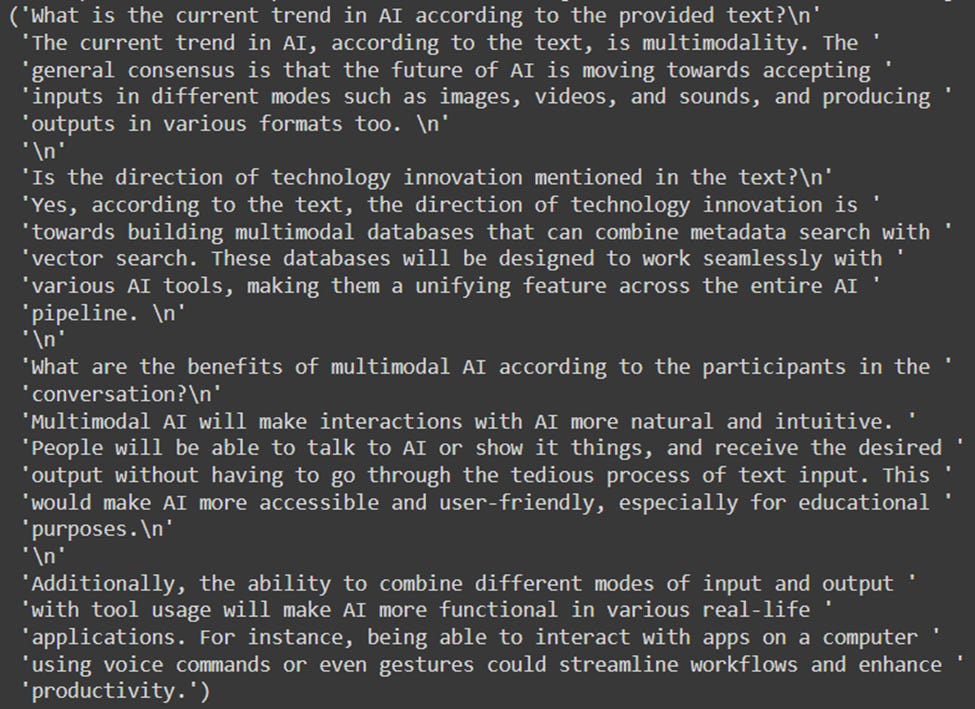
The format of the output can be further preprocessed to make it look nicer, but I wanted to share what the raw output looks like right out of the box.
What’s next?
And there you have it, folks! This brings us to the end of our deep dive into semantic search and chatting with podcast data. While we've explored powerful techniques, we've also seen some of the limitations in accurately retrieving nuanced information. Right now, the output you saw above just shows the text, but you may wonder which podcast the content is from, who the guest was, or what the URL to the podcast is. Hold on to your hats—this isn't the end of the journey. It's just the beginning. Stay tuned, because next, I'll be diving into the knowledge graphs and Retrieval-Augmented Generation (RAG). These advanced methods help to tackle the challenges we've faced and take our information retrieval to the next level. Trust me, you won't want to miss it!
Subscribe now to stay up-to-date!
Originally posted at:
Dive in
Related
Blog
Semantic Search to Glean Valuable Insights from Podcast Series Part 2
By Sonam Gupta • Jul 17th, 2024 • Views 732
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314
Blog
Semantic Search to Glean Valuable Insights from Podcasts: Part 1
By Sonam Gupta • Jun 18th, 2024 • Views 730
Video
Information Retrieval & Relevance: Vector Embeddings for Semantic Search
By Daniel Svonava • Feb 24th, 2024 • Views 1.4K
Blog
Semantic Search to Glean Valuable Insights from Podcast Series Part 2
By Sonam Gupta • Jul 17th, 2024 • Views 732
Blog
Semantic Search to Glean Valuable Insights from Podcasts: Part 1
By Sonam Gupta • Jun 18th, 2024 • Views 730
Video
Information Retrieval & Relevance: Vector Embeddings for Semantic Search
By Daniel Svonava • Feb 24th, 2024 • Views 1.4K
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314