
Semantic Search to Glean Valuable Insights from Podcasts: Part 1

# Semantic Search
# Speech Recognition AI
# OpenAI
# Vector Database
Sneak Peek into AI Chronicles
June 18, 2024
Sonam Gupta

Sneak Peek into AI Chronicles
I got into hosting podcasts to learn firsthand knowledge from people who are building cool AI technologies or applying these technologies and algorithms to real-world problems. Now, over 20 podcasts later and counting, I find myself wanting to revisit and relive those aha moments, and so the idea for this project was born. I wanted to create a way to easily search and rediscover the wealth of knowledge shared in these podcasts, both for my benefit and for anyone else seeking these insights. And so, the “Semantic Search on Podcast Transcripts” series begins. In this multi-part blog journey, we’ll explore the process of building a semantic search application, starting with transcribing podcast episodes and ending with a powerful tool for navigating through the treasure trove of AI-related concepts and ideas shared by my guests.
I have split this series into three stages to methodically build the foundation for a robust semantic search system:
Post 1: Transcribe audio files and store them in the vector database for basic database queries.
Post 2: Embed the text files and store them in the vector database.
Post 3: Use the LLM to perform a semantic search based on user queries.
In this post, I will walk you through the process of transcribing the podcast audio files using OpenAI’s Whisper model and then storing the transcribed text files in a new and upcoming vector database called ApertureDB from ApertureData . Here is the technology used for this part of the series:
Dataset: Podcast audio files (.m4A)
Transcription model: OpenAI Whisper base.en (74M parameters, ~1GB VRAM required, ~16x speed)
Platform: Google Colab (CPU or T4 GPU)
Metadata, embeddings, text storage: ApertureDB
Audio Transcription With OpenAI Whisper
Transcription of any audio or video is essential since it transforms spoken words into written text, enabling various applications like information retrieval, content indexing, and accessibility improvements. For this project, transcription serves as the foundation for building a semantic search engine that can accurately retrieve information from podcast transcripts.
Why did I use OpenAI’s Whisper Model?
There are several options for choosing an audio transcription model, such as Google’s Speech-to-Text, AWS Transcribe, Assembly AI API, OpenAI Whisper, and more. Each of these models has its pros and cons. This article provides a good comparison between some of these models. Most of these large models are built on transformer-based sequence-to-sequence architecture. Whisper is widely used for speech recognition due to its free availability and high-quality transcriptions, making it ideal for the needs of this project without requiring extensive setup.
OpenAI Whisper is an open-source, general-purpose speech recognition model released in September 2022. It was trained on a large and diverse dataset, enabling it to perform multilingual speech recognition, speech translation, and language identification. This model can take audio or audiovisual files (with a size limit of 25 MB) in formats such as mp3, mp4, mpeg, mpga, m4a, wav, and webm as input and transcribe the audio as output, which can be saved in plain text file format. For more technical details, the GitHub repository provides a comprehensive explanation of this model.
What is ApertureDB?
Countless vector databases are available for us to use. Some of the popular ones are Weaviate , Pinecone , ApertureDB , and Milvus , among others. Choosing which of these databases to use is a tough choice because each one has great features to offer, whether it’s their open-source nature, access to multiple index types, scalability, costs, etc. After careful consideration, I chose ApertureDB due to its unique ability to “integrate functionalities of a vector database, intelligence graph, and visual or document data to seamlessly query across data domains.”
ApertureDB is a multimodal database designed to manage and process diverse datasets of different types like images, videos, text documents, and associated metadata. It integrates data management, vector similarity search, and graph-based metadata filtering within a unified API key. The key features include support for ACID transactions, on-the-fly data preprocessing, and scalability for large-scale machine-learning operations. ApertureDB aims to streamline complex data queries and preprocessing tasks, making it a robust solution for handling and analyzing multimodal data in ML workflows. For more information, check out ApertureDB documentation .
Step-by-step Guide to Transcribing Audio Files
Libraries and Installation
To get started, you need to install the Whisper model seen in the following image, and then import the required Python packages:

An ideal way to start the project will be to create a virtual environment and then install the model you can do that as follows:
After you upload the podcast’s audio files in the directory, it's time to run the Whisper model and generate the transcripts.
Running the Whisper Model
The following code snippet iterates through all the audio files you uploaded, transcribes them using Whisper, and saves the transcriptions as text files.
The transcriptions may contain some spelling mistakes but the majority of the content was pretty accurate.Here is a sample screenshot of the transcribed audio:
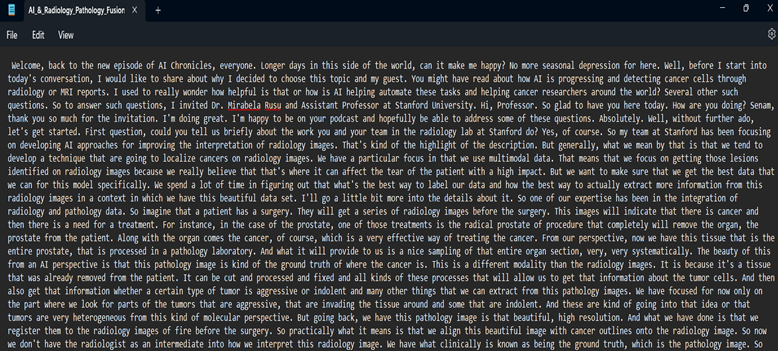
Now that we have the transcribed text files, the next step is to store them in a vector database for basic metadata querying.
Step-by-step Guide to Storing Transcriptions into ApertureDB
1. Setting Up ApertureDB
First, ensure that you have the ApertureDB server installed and running . If you haven’t already done so, you can install the ApertureDB Python client SDK using the following command:
Check the current configuration to ensure you can connect to the database instance:
If this is your first time connecting to the ApertureDB server, you can create a new configuration profile for your project, in this case, for podcast semantic search. This is where you will enter the hostname, port number, etc. For more details, check out the documentation :
Verify the status of the ApertureDB instance:
The output from the above line of code will look something like this:
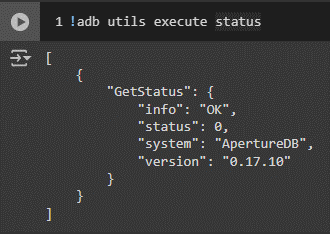
Status verification for ApertureDB instance on Colab
2. Connecting to ApertureDB
Now, let’s connect to the instance. We will use the “aperturedb” python package to connect and interact with the database.
3. Creating the Metadata CSV File
Since ApertureDB can store metadata as a property graph and the corresponding data, I chose to start with a very simple schema for this project. While I build this across this series, for now, let’s introduce the transcript metadata and text as Blob types supported by this database. For that, I created a CSV file named ‘transcripts_ingestion.csv’ (see the screenshot below) containing columns such as ‘filename’, ‘type of file’, ‘format of file’,’ page_url’, ‘constraint_page_url’. The constraint_id or in this case, constraint_page_url makes sure that a blob with the specific id (page_url) would be only inserted if it doesn’t already exist in the database. This documentation on Blob data will have more details.
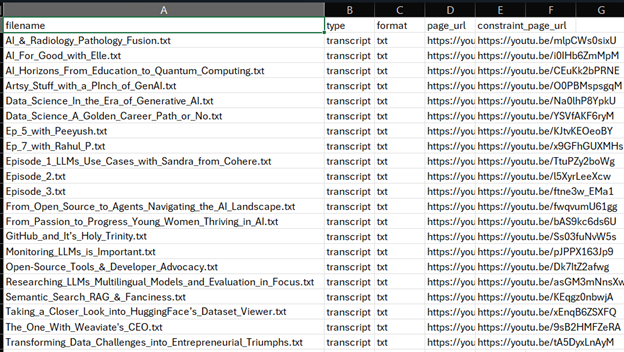
Metadata CSV File
4. Ingesting Transcriptions
Next step is to ingest the transcription data into the database instance. The metadata CSV file ‘transcripts_ingestion.csv’ contains the necessary details as mentioned above. We will use the ‘BlobDataCSV’ class to facilitate this process.
The output will look like you see in the following image:

CSV Ingestion Output
5. Querying the Database
After ingesting the data, we can query the database to ensure the transcriptions have been stored correctly. The following query retrieves all blogs of type ‘transcript’ and returns their properties. There are different Blob commands you can use such as AddBlob, FindBlob, UpdateBlob, and DeleteBlob. To find all the blobs I have in the database, I used it as follows:
From the above code, the output is (the following screenshot shows just the first few entries but in total, there are 23 episodes entered in the database):
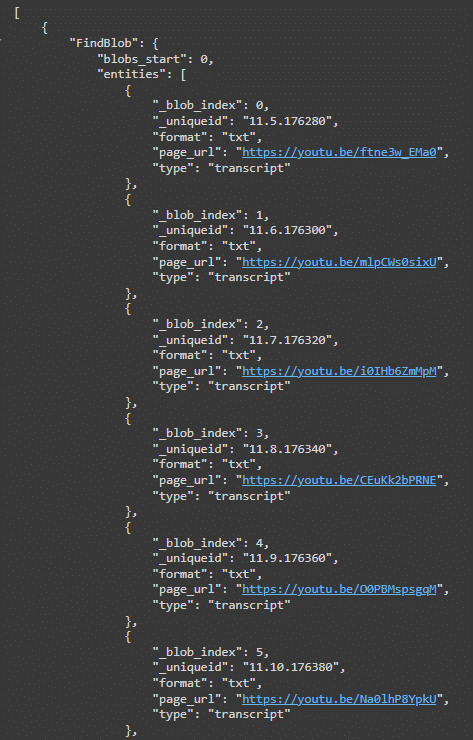
BLOB Insertion into ApertureDB Instance
To verify, we can print the URL of the first transcript entry using the following line of code:
This was the output I received:

Query the Database
We can perform more such queries and check the metadata or retrieve the text file itself if needed.
Conclusion
The fun part about this stage of the project is seeing how accessible content can become with just a few simple steps. Transcription is a powerful tool, and by using OpenAI Whisper, it becomes an efficient process, unlocking the potential for further exploration and analysis.
The choice of tools and technologies is also an enjoyable aspect, with ApertureDB offering a unique and robust solution for handling diverse datasets. It’s exciting to explore these options and discover the capabilities they bring to the project, especially when considering the potential for future development and expansion. Additionally, the satisfaction of knowing that this project will make it easier to revisit and learn from past podcasts is a great motivator. It’s a practical solution with immediate benefits, and that’s always fun to work on!
Originally posted at:
Dive in
Related
Blog
Semantic Search to Glean Valuable Insights from Podcast- Part 3
By Sonam Gupta • Jul 29th, 2024 • Views 586
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314
Blog
Semantic Search to Glean Valuable Insights from Podcast Series Part 2
By Sonam Gupta • Jul 17th, 2024 • Views 732
Video
Information Retrieval & Relevance: Vector Embeddings for Semantic Search
By Daniel Svonava • Feb 24th, 2024 • Views 1.4K
Blog
Semantic Search to Glean Valuable Insights from Podcast- Part 3
By Sonam Gupta • Jul 29th, 2024 • Views 586
Blog
Semantic Search to Glean Valuable Insights from Podcast Series Part 2
By Sonam Gupta • Jul 17th, 2024 • Views 732
Video
Information Retrieval & Relevance: Vector Embeddings for Semantic Search
By Daniel Svonava • Feb 24th, 2024 • Views 1.4K
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314