
Semantic Search to Glean Valuable Insights from Podcast Series Part 2

# Podcast Transcripts
# Cohere
# ApertureDB
From Embedding Podcast Transcripts with Cohere to Efficient Storage and Retrieval in ApertureDB
July 17, 2024
Sonam Gupta
Remember how I mentioned in my previous blog post that I would embed the podcast transcripts and store them in a vector database? Well, I did it! If it’s still on your to-do list, now’s the time to mark that task done. Here is a quick recap of what I covered:
ü Gave a brief overview of the audio transcription model Whisper from OpenAI and the graph vector database called ApertureDB from ApertureData
- Generated audio transcripts into text files
- Set up the database instance
- Stored the text files through command line ingestion into the database
- Performed some basic DB querying to extract URLs of the podcast episodes
I hope that jogged your memory and got you curious enough to read the first post of this semantic search blog series again. It’s simple, just click here to read, like it, and follow along so you can connect the dots to what I am about to share in this one. 😊
In this post, I will tell you exactly what I did and learned while embedding the transcripts and then storing them in ApertureDB. Here are the tools and data used for this part of the series:
Dataset: Podcast transcripts (.txt)
Platform: Google Colab (CPU or T4 GPU)
Embedding Transcripts with Cohere’s embed-v3
One of Cohere’s strengths is its embedding model. With the new embedding model, they released last year, embed-v3, we see a powerful upgrade from previous versions. This model excels at evaluating how well user queries match the topics and content quality of the available documents. It ranks high-quality search results effectively, which is particularly beneficial for noisy, unstructured datasets. Cohere embeddings support multilingual datasets and are available in different dimensions. Benchmarking evaluations have shown that the performance of these embedding models is impressive. Here's a brief overview of the key points:
- Powerful Upgrade: embed-v3 is a significant improvement over previous versions, enhancing the matching accuracy between user queries and document topics.
- Quality Ranking: The model excels at ranking high-quality search results, a crucial feature for handling unstructured and noisy data.
- Multilingual Support: Cohere embeddings can process datasets in multiple languages, making them versatile for various applications.
- Dimensional Flexibility: They come in different dimensions, providing flexibility for different use cases and data complexities.
Choosing Your Embedding Model
Overall, Cohere’s embed-v3 offers robust performance and versatility, making it an excellent choice for embedding and querying our podcast transcripts:
There are many embedding models available for us to use, such as OpenAI’s text-embedding-3-small and text-embedding-3-large, Mistral’s E5-mistral-7b-instruct, and many more. At the end of the day, the choice depends on your use case, the availability of these embedding models, compute costs, performance, and accuracy. So far, from my experience and from reading comparisons online , Cohere was the strongest choice as its accuracy is still the best, especially for semantic search applications.
Chunking Before Embedding
Given that the transcripts are long-form text, chunking was the smart choice to start the embedding process as it optimizes the text embedding process, making it more efficient, accurate, and scalable. There are quite a few chunking strategies to choose from, for instance, you can chunk text by splitting it into tokens, characters, paragraphs, and semantic boundaries. For a detailed comparison, check out this article where the author explains different chunking strategies and how to evaluate them. LangChain provides support for many of these chunking strategies and the one I used in this project is token text splitting with overlap. Here’s how:

Output of chunking:
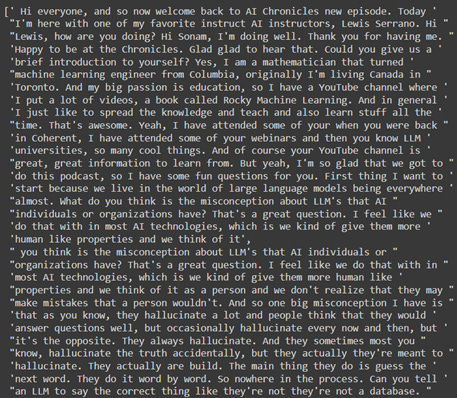
Setting some overlap between the chunks is a good idea to ensure the context isn’t lost. You can assess the value for the chunk_size and chunk_overlap based on several factors such as the nature of your content, the embedding model in use, and the use cases for which you used chunking. In this project, I tried a few ranges of chunk size and overlap until I decided on the value that seemed feasible. One thing to note is given the maximum token length allowed by the embedding model can play an important role in choosing an optimal chunk size. For Cohere’s embed-v3.0 basic model, the maximum token length is 512.
Now onto the fun part: embedding these chunks. It’s straightforward with frameworks like LangChain and all the integrations that come with it. The following code continues from the snippet you saw above for chunking:

Did you notice how I saved the embeddings in a numpy file to my local machine? This is quite helpful if you want to return to your program later and avoid embedding your data again. Now, it’s time to call the above methods:

Once you have embedded the dataset, it’s time to save it to the vector store or database of your choice. In this case, as mentioned in the previous post, I saved my dataset and embeddings in ApertureDB as shown below:

Let’s break down the code above. To ingest your embeddings into ApertureDB, you need to follow a few steps. (A little birdie told me there would be an ApertureDB LangChain integration coming up soon, so the following process can be replaced with fewer lines of code…):
- Create a descriptor set. What is a descriptor set, you might wonder? Imagine this, “Descriptor sets are like different produce aisles in a supermarket. Each aisle has a specific type of fruit or vegetable, organized and separated from other items. They are essential because they ensure that when you search for, say, apples, you are only shown apples, not oranges or potatoes. Before you can buy the apples, you must go to the descriptor set aisle first. Then you can choose which apple variety you'd like help with.” [Analogy given by the chatbot from the ApertureData documentation]. For my data, the descriptor set had fixed values of the name of the descriptor set, dimensions, distance metric, and indexing engine. For more understanding, a descriptor set is similar to what Milvus and Qdrant call a collection.
- If you recall, we ingested a CSV file with the dataset details using the command line command: adb ingest from-csv --ingest-type=BLOB transcripts_ingestion.csv. The columns in this file can be used as metadata for further querying and output in your semantic search queries. In this case, the properties I am interested in seeing in the output are the title of the podcast, the guest's name, the transcript text, and the YouTube URL of the episode. You can define these properties in the command called AddDescriptor. You can create descriptors for each of your files in the database. More details on these commands can be found here .
- Parallel Loader is a great tool ApertureDB offers that lets you ingest the data into the database in batches. This comes in handy when you have large-scale data. More details are on this page .
And the output looks something like this:

Didn’t understand what the above weird-looking output meant? Want a better visual of your output? Check it out:
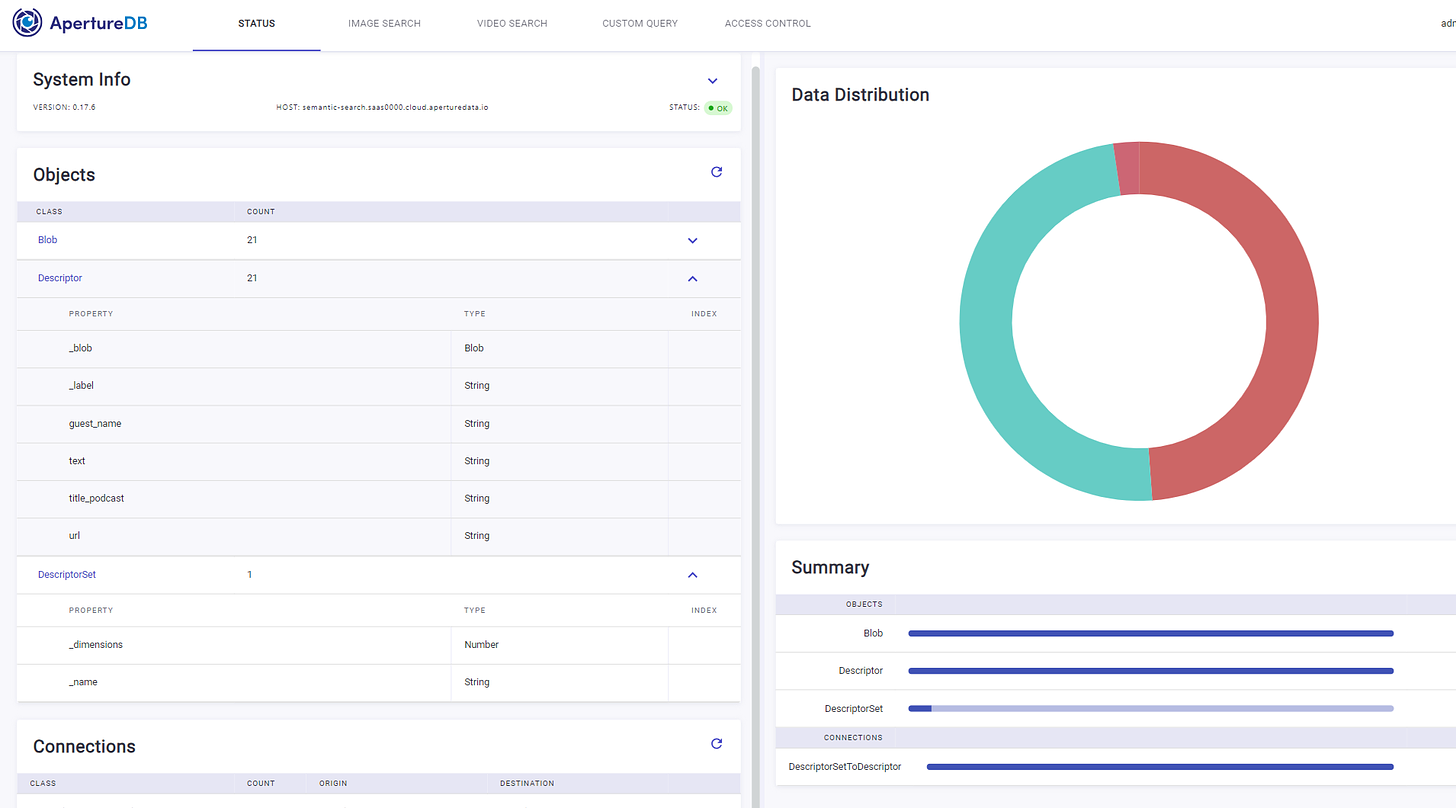
Next up, is calling the semantic search engine to answer your questions. Finding contextually similar results to whatever you ask the system using the content you provide which in this case are the podcast transcripts. Following is how you can query the ApertureDB to find relevant answers to your questions:
.
.
.
Just kidding! Semantic search is the 3rd blog in this series… Stay tuned. Until then, I hope you learned cool stuff and want to start building this for yourself. Be kind and share your feedback with me (DM, comments, text message, buy me a coffee 😊, anything works,) Ciao!
References:
- Try out ApertureDB sample demos: https://www.aperturedata.io/demo-request
- Try out Cohere’s embed models: https://dashboard.cohere.com/playground/embed
Originally posted at:
Dive in
Related
Blog
Semantic Search to Glean Valuable Insights from Podcast- Part 3
By Sonam Gupta • Jul 29th, 2024 • Views 586
Blog
How to Build Your First Semantic Search System: My Step-by-Step Guide with Code
By Sonam Gupta • Jan 5th, 2024 • Views 1.1K
Blog
Semantic Search to Glean Valuable Insights from Podcasts: Part 1
By Sonam Gupta • Jun 18th, 2024 • Views 730
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314
Blog
Semantic Search to Glean Valuable Insights from Podcast- Part 3
By Sonam Gupta • Jul 29th, 2024 • Views 586
Blog
Semantic Search to Glean Valuable Insights from Podcasts: Part 1
By Sonam Gupta • Jun 18th, 2024 • Views 730
Blog
Vector Similarity Search: From Basics to Production
By Samuel Partee • Aug 11th, 2022 • Views 314
Blog
How to Build Your First Semantic Search System: My Step-by-Step Guide with Code
By Sonam Gupta • Jan 5th, 2024 • Views 1.1K