
Creating a PDF Query Assistant with Upstage AI Solar and LangChain Integration

# PDF Query
# AI Solar
# LangChain
Chat with multiple PDF files
June 5, 2024
Sonam Gupta

Do you ever feel overwhelmed by the numerous research papers you need to read? As someone who just finished a PhD, I know it’s no walk in the park to sift through a huge pile of PDFs. Sometimes, you just want simple answers like, “What is this research paper about?” or “What are the basic use cases of an embedding model?” Wouldn’t it be great to have a chat assistant dedicated to answering questions based on the PDFs you provide?
In this blog post, I’ll describe how I built a chat assistant using the upcoming LLM called Solar from Upstage AI , integrated with LangChain . The goal of this project is to explore how Upstage AI models work with LangChain integration to create a tool for interacting with PDF files. LangChain streamlines PDF data retrieval and interaction, and I’ll discuss this in more detail in the following sections.
Section 1: Understand the Technology
Upstage AI Models:
Embedding Model: There is a plethora of embedding models out there for us to try. The Solar embeddings API lets you access two new embedding models they provide solar-embedding-1-large-query and solar-embedding-1-large-passage. Both models offer a 4k context length and can be used to embed user queries and large passages of text, respectively. In the most recent LLM benchmarking, these embedding models surpassed the performance of OpenAI models as seen in Solar Embedding 1 Large . In this post, I used solar-embedding-1-large-passage to vectorize the large text from PDF files.
Layout Analysis Model: PDF documents are not our usual text files as they often contain complex layouts with multiple columns, tables, images, and more such elements. As much as this diversity of elements is appreciated, it comes with complexities that are difficult to handle with the typical file parsers available in Python. Using traditional PDF readers like PyPDF may or may not lead to a loss of context or return data in an unorganized manner where the tables and structured data can become jumbled. Layout analysis helps to preserve the original structure of the document assuring that the extracted context maintains its intended format and meaning.
With models like Upstage’s layout-analysis-0.2.1, loading and parsing not only the PDF files but also images in different formats (.png, .jpeg, etc.) has become much simpler. An example using the layout-analysis-0.2.1 model: the output from parsing the invoice image provides a structured JSON output, where each HTML tag from the image is shown. In this project, I used this model with LangChain integration to load multiple PDF files. The parameters of this model allow you to split the loading of the file page by page and categorize all the HTML tags from the file, making it easier for further analysis, such as categorizing tables, figures, main text content, and more. For more information, check out: https://developers.upstage.ai/docs/apis/layout-analysis
Chat Model: Along with embedding models and layout analysis models, Solar also provides API access to chat models: solar-1-mini-chat and solar-1-mini-chat-ja, which cover multilingual capabilities in English, Korean, and Japanese. Both these models support over 32k context length. The multilingual capabilities open several opportunities for building a chat assistant using this model. Utilizing these chat capabilities, I used the solar-1-mini-chat model to ask questions or interact with the PDF files, using them as the context on which the model bases its answers.
LangChain Integration:
Many of us are familiar with LangChain. However, to put it simply, LangChain is an open-source framework that streamlines the connection between various LLMs and external data sources. This framework is widely used by organizations and developers building LLM applications. Due to its popularity and ease of use, LangChain integrates with various LLMs and vector stores. Any developer can build and scale a chat assistant, semantic search application, and more in just a few lines of code. The framework simplifies every stage of the LLM application lifecycle. In this project, as mentioned above, I used LangChain integrations with Upstage models and the vector store FAISS to store the embedded PDF files.
In the next section, I will walk you through the setup used in this project.
Section 2: Project Setup and Configuration
Environment Preparation:
- I spun a CPU instance on Google Colab and saved my dataset on it. Since this is a small-scale project, I did not need GPU instances. Another benefit of Google Colab is the easier installation of libraries.
- API key can be accessed from the Upstage AI console. You will need to make an account.
Dependencies Installation:
- Simple pip commands to install the required packages should suffice as seen in the following image:

Fig 1. Dependencies Installation
Section 3: Loading and Embedding PDF Files
Loading any PDF file Using the UpstageLayoutAnalysisLoader model is easy since I used multiple files. To use the model, you must pass your API key first. I simplified it by using the following code:
After loading the file, the next step is to generate embeddings and store them in a vector store of your choice. With the LangChain integration, you have several options for both embedding models and vector stores. For this project, I used FAISS, an open-source library from Meta that enables fast similarity search and clustering of dense vectors.
For larger and multimodal datasets, other vector databases like ApertureDb , Weaviate , Milvus , etc., could be better choices, depending on your specific use cases.
Next, I will show how the basic retriever model could be to retrieve the information from the PDF files and then build the chat assistant.
Section 4: Retriever and Chat Models
- Retriever: A retriever interface is simply used to retrieve the information from your dataset based on the user’s unstructured search query. There are several retrieval algorithms, meant for different purposes, such as multi-vector, self-query, and contextual compression among others. More details can be found on LangChain’s Retrievers page. Since I saved the embedded documents in the FAISS vector store, I used the vector-store retriever as follows:
- Chat Model: Creating a good prompt to query the model is essential to get as accurate, clear, and precise results from the LLM, as possible. Thus, using a template to make sure the LLM understands instructions is a safer idea. In this project, I passed the following template:
You can always add more details in the prompt tailored to your use cases. LangChain provides a function called ChatPromptTemplate that you can use to chain the prompt and model together in a more structured fashion before you start chatting with the assistant as seen in the following code snippet:
The prompt template on LangChain allows you to add human messages, chat assistant messages, the string variables for the user query, and the context variable (retriever in this case) to use. To create a custom chain, you can use the Runnable protocol from LangChain. In the code snippet above where the chain is initialized, context is the variable that will hold the value returned from the retriever whereas the query will go through the placeholder from runnable protocol and be passed as is without any modification. The last line in the chain is where the prompt given will be sequentially passed to the model and the output from the model will be fed into StrOutputParser which parses the output in the desired format.
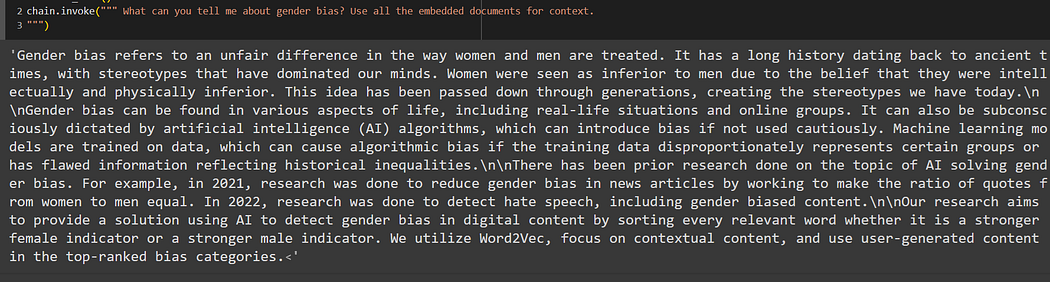
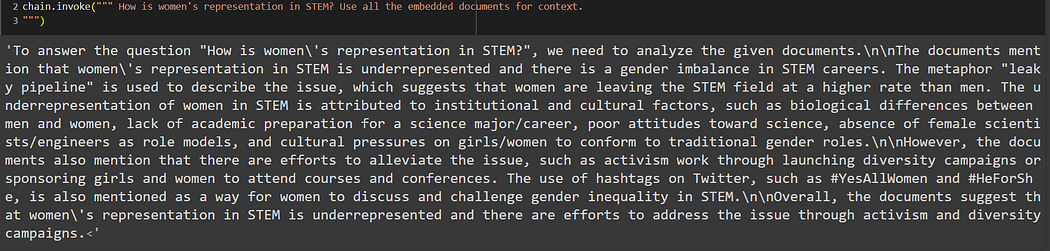
The last step is to invoke the chat model by passing the user query and here are some of the example query results:

Ref PDF files 3 & 4
Section 5: Advantages and Applications
Having a chat assistant for your files could act as a great research assistant while you work on any project or research. It speeds up the process of retrieving information from a huge pile of data. When a user inputs a query, the assistant can instantly search through the embedded documents, retrieve the most relevant sections, and present concise answers. This eliminates the need to manually read through each document, making the research process faster and more efficient.
The chat assistant’s use of Upstage AI’s Solar embeddings ensures that it understands the context and semantics of the documents. This means it can accurately match user queries with the most relevant content, reducing the chances of retrieving irrelevant information.
General Use-cases:
- Academia: Researchers and academics could use such a chat assistant to quickly access important information from several research papers, theses, articles, and more. This could come in handy when summarizing literature reviews, or even summarizing large documents.
- Legal: Lawyers could save time using such an assistant while combing through large case law studies, and any other legal documents.
Model Customizations:
- The embedding and other models can be fine-tuned on any specific domain data to build more contextually relevant retrievers or other LLM applications. General embeddings such as those provided by BERT, or basic GPT may not be optimized for specific domain applications. These models are trained on a vast amount of data from the great internet but that also means they might not capture the domain-specific knowledge and contextual meanings. Thus, custom embeddings are essential in such cases since they could ensure that the semantic representation of the input documents aligns closely with the specific context of the domain. This increases the accuracy of the output from information retrieval allowing the chat assistant to provide precise and contextually relevant answers. The solar-embedding model offers a high-dimensional space (e.g., 4096 dimensions) that provides a detailed vector representation of the documents and returns more accurate semantic search results.
- The chat assistant’s interface can be customized to integrate seamlessly with existing systems and workflows, whether it’s a web application, a mobile app, or desktop software.
Conclusion
To recap, building a basic chat assistant for PDF files involved initiating an embedding model, storing those embeddings in a vector store, and then building the chat model using Upstage’s Solar models. The process was simplified using LangChain integration with the Solar models. This application can be further improved by expanding the dataset, using a vector database to enable better similarity search and querying metadata if required, and providing a more detailed prompt template. The chat LLM could be fine-tuned on the dataset of PDF files and an advanced RAG component could be incorporated to generate more accurate and higher-quality results.
For developers, I strongly recommend using LangChain integration and exploring other models, databases, retriever models, and similar functionalities.
References:
Originally posted at:
Dive in
Related
Video
Architecting Modern AI Systems: Platforms, Agents, and Integration
By Allen Roush • May 28th, 2026 • Views 48
Blog
mAIdAI: Building a Personal Assistant with Google Cloud and Vertex AI
By Médéric Hurier • Mar 10th, 2026 • Views 112
Video
Building Context-Aware Reasoning Applications with LangChain and LangSmith
By Harrison Chase • Oct 18th, 2023 • Views 798
Blog
mAIdAI: Building a Personal Assistant with Google Cloud and Vertex AI
By Médéric Hurier • Mar 10th, 2026 • Views 112
Video
Building Context-Aware Reasoning Applications with LangChain and LangSmith
By Harrison Chase • Oct 18th, 2023 • Views 798
Video
Architecting Modern AI Systems: Platforms, Agents, and Integration
By Allen Roush • May 28th, 2026 • Views 48