
DISTRIBUTED TRAINING IN MLOPS: Accelerate MLOps with Distributed Computing for Scalable Machine Learning

# MLOps
# Machine Learning
# Pytorch
# Kubernetes
# Cloud
Enable your MLOps platform to train bigger and faster at all scales — because your models deserve a “team effort”
March 11, 2025
Rafał Siwek

Why burn out alone when you can distribute the load? (Image AI-Generated using Ideogram 2.0)
Machine Learning works in part because of massive datasets and billions of parameters. In these cases, running experiments on a single machine is not just slow. For example, training a model with 175 billion parameters would take 288 years on a single NVIDIA V100 GPU. It is also often impossible due to hardware limits. Either the training data is too large, or the model’s scale exceeds what a single card can handle.
An MLOps platform with the right working plane configuration and implementation strategy for distributed computing can:
- Unlock scales unattainable for single machines
- Significantly reduce training time
- Enable faster iterations to achieve model goals
- Optimize the utilization of available devices
With this article, I introduce my mini-series on distributed processing in MLOps. I detail real-world implementations and offer actionable insights on how organizations can optimize their GPU-accelerated infrastructures and heterogeneous configurations to increase the performance of their machine-learning workflows.
In this first part, I will:
- Introduce strategies for distributed processing.
- Explore local and production-level implementations for MLOps platforms through practical examples.
- Discuss maintenance approaches, including monitoring and fault tolerance.
See other articles in this series:
How to Efficiently Use GPUs for Distributed Machine Learning in MLOps
How Industry Giants Slash Machine Learning Training Costs and Achieve 5.6x Speed Boosts
Break GPU Vendor Lock-In: Distributed MLOps across mixed AMD and NVIDIA Clusters
Unlocking the forbidden cloud hack: Running distributed PyTorch jobs on mixed GPU clusters with AWS NVIDIA g4dn and AMD…
The scenario
A typical scenario involves a data scientist developing experiment code locally and needing to scale it to handle a much larger dataset and/or distribute the layers of a larger model across multiple devices. This often needs to be achieved within a concise timeframe.
We assume the model fits on a single device for this example, but the dataset is large. Consequently, we’ll employ the popular Distributed Data Parallel (DDP) strategy.
Let’s explore the options for achieving this goal. We’ll examine the required code adjustments and deployment processes for different environment configurations.
Cloud infrastructure setup, code, and detailed instructions are available in my repository:
GitHub - RafalSiwek/distributed-mlops-overview: An exploration of distributed processing solutions…
An exploration of distributed processing solutions for MLOps. - RafalSiwek/distributed-mlops-overview
Distributed processing strategies
Training machine learning models on massive datasets using traditional, sequential methods often leads to long training times and low efficiency. While optimization methods like sequential training, adjusting numerical precision, or upgrading to bigger GPUs can help, they hit limits as model size or data volume grows.
For models that can’t be trained or served without distributed methods, consider large language models (LLMs) like GPT-4 or Llama-3, which contain trillions of parameters. These models can’t be trained on a single GPU as they simply do not fit into the device's memory limits. Even smaller models trained on petabyte-scale datasets (e.g., recommendation systems at Netflix or Amazon) face a “distributed or nothing” dilemma, as storing and processing such data on a single machine is impractical.
Distributed strategies balance the computational load and memory footprint by partitioning the model and dataset across multiple nodes. This improves scalability and efficiency, unlocking training capabilities that single-device techniques can’t achieve.
Initially, distributed processing in machine learning focused mainly on model training, using two dominant strategies: parameter servers and collective peer-to-peer (P2P) communication primitives like the ring-based all-reduce pattern:

Parameter Server architectures (left) may use more bandwidth and resources but can be fault-tolerant and support asynchronous updates. In comparison, P2P Collectives (right) use less bandwidth but are mostly synchronous, potentially limiting fault tolerance and performance in high-latency networks.
Nowadays, with the growing demand for ML-based solutions and advancements in hardware and stable implementations, a more comprehensive approach has emerged. This approach addresses not only training but also distributed serving:
- The parameter server paradigm is useful for federated learning with varying device access. It involves two entities: the parameter server, which manages model parameters, and workers, which compute on data subsets and sync independently with the server for updates. This approach handles worker failures well but adds complexity and requires careful balancing of the worker-to-server ratio. Too few parameter servers can cause network communication bottlenecks.
- Use data parallelism for models that fit on a single device but require larger batch sizes or faster experimentation. Here, the model is copied across multiple processes or machines, where each processes a subset of the data in parallel.
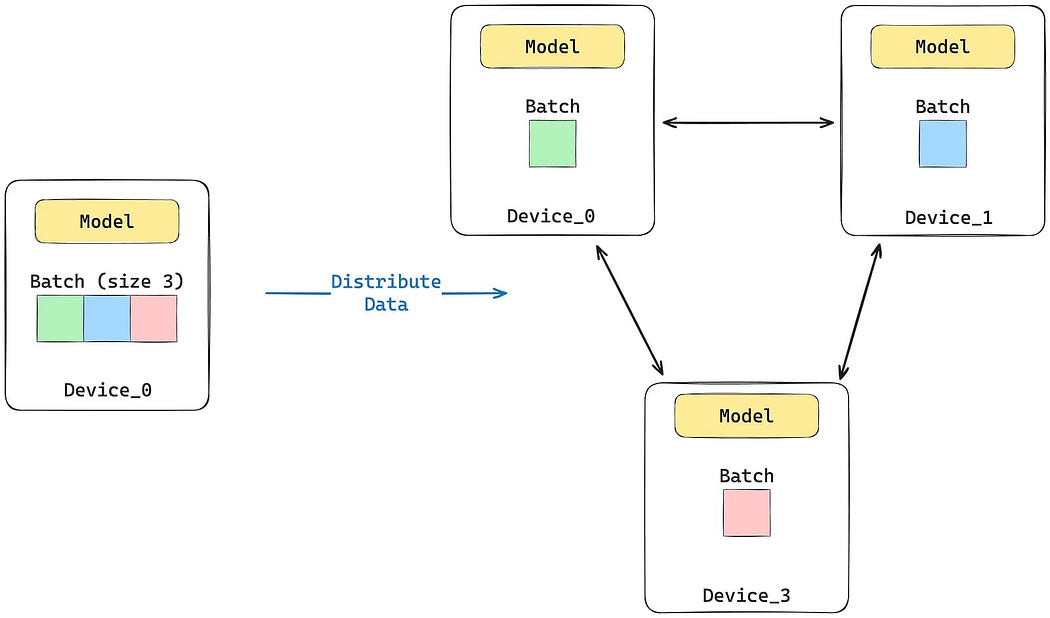
Data Parallelism
- Use tensor parallelism for models with tensors so big that they don’t fit on a single device. Here, the model is split horizontally — each device processes a chunk of the tensor in parallel, and the results are synchronized at the end. Depending on the model, tensor parallelism may require a greater network bandwidth and a single node with multiple devices to address the required throughput.
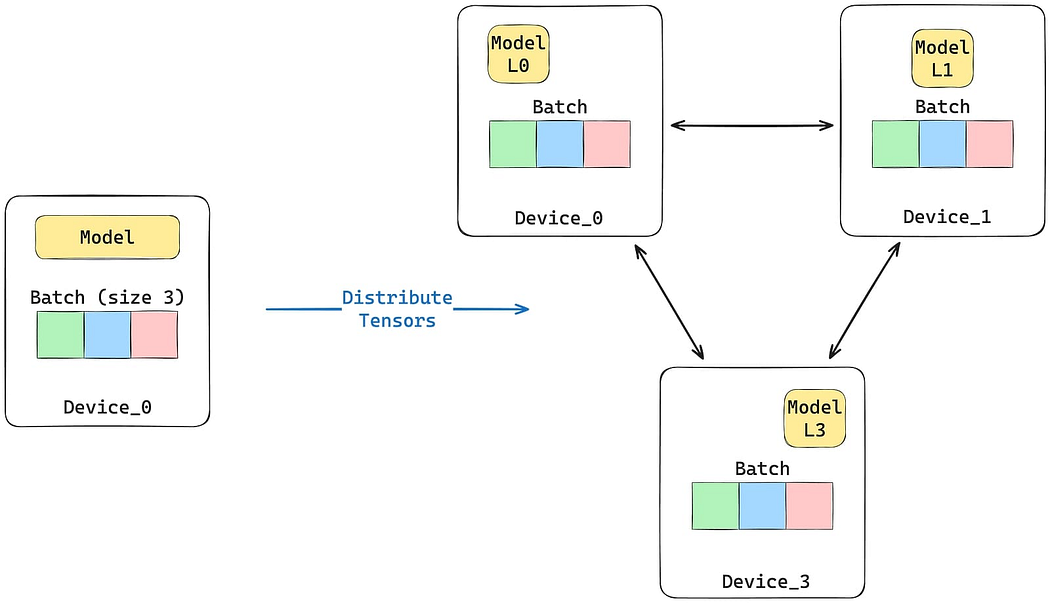
Tensor Parallelism
- For sequential models with many layers, such as neural networks or transformers, that exceed the memory capacity of a single machine, pipeline parallelism is suggested. Here, the model is split into stages, each assigned to a separate device or node, allowing for overlapping computation and communication.

- A combination of different parallelism strategies is used for large models with billions of parameters. Approaches like the Zero Redundancy Optimizer (ZeRO) or Fully Sharded Data Parallel (FSDP) ensure optimal performance. Additionally, multi-dimensional hybrid strategies can be applied to break down more significant problems into smaller, manageable sub-problems.
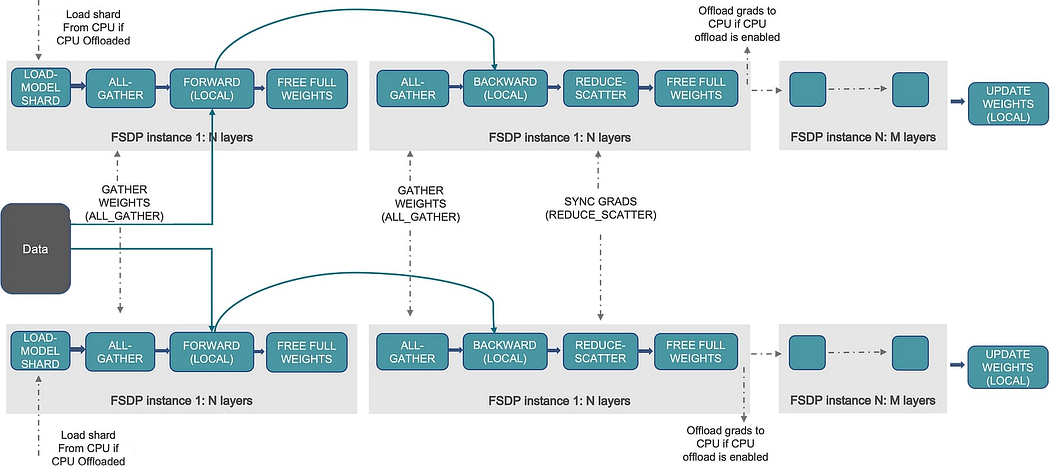
Distributed processing strategies are crucial for modern machine learning. From parameter servers and P2P collectives to hybrid techniques like ZeRO and FSDP, each strategy addresses specific challenges in scalability, efficiency, and resource constraints. Whether splitting data across devices (data parallelism), slicing tensors (tensor parallelism), or chaining layers across nodes (pipeline parallelism), the choice depends on your model’s size, data volume, and infrastructure.
Distributing the experiment code
Training machine learning models at scale often hits a wall when fine-tuning larger architectures or expanding datasets. Single-device setups get overwhelmed, pushing teams to adopt distributed solutions. However, migrating from local experiments to distributed environments introduces hurdles. Teams must rework code for multi-device communication, manage fragmented data, and adapt workflows designed for small-scale prototyping. Data scientists face unfamiliar tools, debugging across nodes, and balancing efficiency with added complexity in their daily tasks.
Modern ML libraries and frameworks, such as PyTorch , TensorFlow , PaddlePaddle for model training, Ray Serve , Triton Inference Server or vLLM for serving, provide distributed processing strategies through user-friendly APIs and modules. However, despite the ease of use these implementations offer, enabling locally developed experiments to run in distributed environments typically requires the following modifications:
1. Distributing the model — Devices must communicate after each epoch to share gradient calculations or manage model layers across devices. This can be implemented manually using available collective operations or handled by “wrapping” the model in distributed wrappers provided by the chosen framework. These wrappers abstract the underlying collective operations and do the heavy lifting:
— PyTorch: torch.nn.parallel.DistributedDataParallel— TensorFlow: tf.distribute.Strategy— PaddlePaddle: paddle.distributed.DataParallel
Example (PyTorch):
2. Distributing the dataset — Similarly to the model distribution challenge, the dataset must be split between devices — and again, this can be done manually or using modules provided by the framework:
— PyTorch: torch.utils.data.distributed.DistributedSampler— TensorFlow: tf.distribute.DistributedDataset with tf.distribute.Strategy.experimental_distribute_dataset— PaddlePaddle: paddle.distributed.DistributedBatchSampler
Example (PyTorch):
3. Process group management — To manage the number of training entities, communication, and resource allocation for each worker and effectively integrate with the Distributed Model and Dataset implementations:
— PyTorch: torch.distributed.init_process_group— TensorFlow: tf.distribute.MultiWorkerMirroredStrategy— PaddlePaddle: paddle.distributed.init_parallel_env
4. Defining the communication strategy — Depending on the chosen distribution strategy, the following needs to be considered:
— Implement the parameter server or configure P2P collective strategies— Select and configure the appropriate communication backend (RPC, Gloo, MPI, UCC or NCCL) to be used by the process group
5. (Optional) Training loop modification — When managing a custom training loop, it might be required to update it to handle the distributed Model and Dataset
In conclusion, migrating from local experiments to distributed environments may seem daunting at first, requiring code modifications for model and dataset partitioning, communication setup, and process group management. However, the benefits far outweigh these challenges. Modern frameworks have simplified much of the complexity, allowing data scientists to harness distributed processing with minimal friction. By distributing models and data across multiple devices, teams can overcome memory constraints, accelerate training times, and scale their experiments to new levels. This transition enhances efficiency and unlocks the potential for training larger and more sophisticated architectures, paving the way for robust, production-ready machine learning systems.
From Prototype to Production: Scaling with Purpose
Distributed training addresses critical barriers in modern machine learning: models too large for single devices, datasets too vast for sequential processing, and timelines too tight for inefficient workflows. As explored in earlier chapters, distributing workloads across devices unlocks scalability — accelerating training, overcoming memory limits, and enabling architectures once deemed impractical. Yet, the actual value of these strategies emerges only when models transition from experimentation to deployment.
Deploying to distributed environments bridges the gap between theoretical gains and real-world impact. Depending on the team and organization size, configurations can range from local setups with multiple GPUs (e.g., a developer workstation) to small-scale clusters of connected machines, cloud-based instances like AWS EC2, or enterprise-level data centers. Each tier introduces unique challenges — like balancing cost, network latency, and hardware compatibility — but shares a common goal: maximizing resource efficiency while minimizing complexity.
While implementations for frameworks like PyTorch, TensorFlow, and PaddlePaddle follow similar principles, this chapter uses a concise PyTorch example to demonstrate core concepts. By training a simple linear layer model in a distributed setup, we highlight universal workflows — such as process group initialization, gradient synchronization, and dataset partitioning — that apply broadly across frameworks and infrastructures.
This guide focuses on practical deployment strategies, showing how to:
- Adapt workflows to infrastructure scales — from local workstations to small/moderate-scale clusters (managed via tools like MPI or Ray) and enterprise-grade systems (orchestrated with Kubernetes) — without rewriting core logic.
- Leverage framework-native tools like PyTorch’s torchrun for lightweight orchestration and production-grade solutions (e.g., Kubernetes operators, Ray clusters, or MPI-based workflows) to automate multi-node coordination and fault tolerance.
- Evaluate vendor-managed platforms (AWS SageMaker, Google Vertex AI, Azure ML, Run:ai, Databricks) for ease of use, flexibility, and cost trade-offs, ensuring alignment with team size, budget, and scalability needs.
By aligning deployment practices with the motivations behind distributed training — speed, scalability, and feasibility — teams ensure their models train faster and deploy smoother, turning ambitious research into robust, production-ready solutions.
Local environments
In local setups, distributed processing is commonly used to accelerate the training process by maximizing the utilization of available devices. It can be applied to a single machine with multiple GPUs, dedicated “AI accelerator stations” like the NVIDIA DGX Station, or cloud-based instances.

Distributed training on a local multi-GPU machine is about utilizing all available resources — in this case, running training jobs on every GPU device
In a relatively compact setup, where all resources are allocated to a single experiment, distribution can be managed by sharing devices within a single process or spawning multiple process instances, each assigned to a specific device. The latter approach, utilizing multiprocessing, is generally preferred since dedicating a process to each device avoids the performance bottleneck imposed by Python’s GIL. In this context, the P2P collective spawned processes are called ranks, each assigned a unique number. Rank 0 is typically designated as the “master rank,” and is often tasked with additional responsibilities such as snapshotting or publishing metrics.
Launching experiments in such environments using PyTorch requires minimal effort. After migrating the necessary code, the remaining steps involve either manually populating process group initialization parameters (MASTER_ADDR, MASTER_PORT, rank information) and launching the processes with torch.multiprocessing, or leveraging the torchrun elastic launcher. The latter, apart from features like failure handling, automatically sets the required initialization variables:
Training the model on a single device machine vs. a multi-device 4x NVIDIA T4 GPU machine (AWS G4dn.12xlarge instance)
The distributed strategies discussed — data, model, and pipeline parallelism — are theoretical concepts and practical enablers for training and fine-tuning some of today’s most impactful models. By leveraging multi-GPU setups (e.g., 4–8 GPUs per node), teams can tackle previously infeasible models.
Moderate-size clusters
When machine learning models grow too large for single machines — think trillion-parameter language models or petabyte-scale datasets — organizations must scale beyond single multi-device nodes. These cases demand moderate-scale clusters (e.g., 10–100 nodes — locally or cloud instances) or High-Performance Computing (HPC) systems to handle workloads that single nodes cannot process efficiently. For example, training a model like GPT-3 (175B parameters) requires splitting layers across hundreds of GPUs using tensor and pipeline parallelism. At the same time, climate simulations or genomic analysis in scientific domains need clusters to process massive, unstructured datasets.

Distributed training on a moderate-sized HPC cluster enables the training of previously unmanageable model sizes by launching training jobs on multiple machines
Launching distributed jobs in these environments, among others, introduces these considerations:
- Environment management: Experiments often require dedicated environments, including specific framework libraries or device versions. Switching machine environments between experiments (“retooling”) can increase the time between consecutive runs. A good approach is to run the workload in containerized environments like Kubernetes or with scheduling agents, supporting environment isolation and pre-init workflows like Ray Cluster.
- Multi-device job launching: When datasets and models surpass the capacity of a single machine, they can be distributed across multiple machines. However, this challenges interconnecting the processes on different devices and ensuring they are synchronized for a specific experiment.
- Logs and monitoring: Distributed training across multiple devices necessitates centralized logging to aggregate process outputs into one location, enabling straightforward examination and monitoring.
- Network performance: When the job is distributed over multiple machines rather than all available devices within one host, the network bandwidth interface utilization becomes a significant factor in enabling performant gradients exchange between ranks.
Moderate clusters are ideal for mid-sized to large teams (e.g., 10–50 engineers) in research labs, AI startups, or enterprises expanding into AI. These teams typically:
- Have the resources to manage cloud instances or on-premise hardware.
- Collaboration across roles is required (data scientists, ML engineers, DevOps).
- Need to balance cost and performance, avoiding over-provisioning 13.
For example, a biotech firm analyzing genomic data might use an HPC cluster to run drug discovery simulations alongside ML workloads, leveraging shared infrastructure for both tasks 16.
Below are examples of how to deploy a distributed PyTorch job to such a cluster:
Elastic launcher:
Torchrun is a built-in tool that is also designed to run training jobs across multiple machines. To enable a multi-node job, each worker must be configured with a consistent environment setup and have the same training code loaded.

Launching distributed jobs with torchrun requires loading the training code and running the launch command for each node separately
To launch a training job, the torchrun command is executed on each worker . The command specifies parameters such as the number of workers, processes per worker, each worker's rank number, and the address of the rendezvous endpoint (commonly hosted on the master node):
Torchrun distributed job on two AWS EC2 T3.xlarge instances with up to 25 Gbps network bandwidth
Torchrun distributed job on two AWS EC2 T3.xlarge instances with up to 25 Gbps network bandwidth
With the elastic launcher, each worker operates within its runtime environment. However, aggregating logs and metrics into a centralized location requires additional effort, typically involving the master rank or alternative implementations like PyTorch Lightning .
MPI launcher (mpirun)Managing individual launch commands on each node become inefficient and error-prone as the cluster grows. The MPI interface with its launcher implementations ( OpenMPI , MPICH , MVAPICH ) provides an alternative, allowing the job to be initiated with a single mpirun command from the master node. This approach simplifies the process, ensuring scalability and reducing the risk of errors during deployment.
The main feature of the MPI launcher is the introduction of a central entity — the launcher — that is responsible for starting jobs and gathering outputs from workers. It also allows flexibility in configuring aspects like the transport layer and collectives backend to fully utilize the supported network capabilities. When using MPI as PyTorch’s collective backend it requires PyTorch to be built with MPI support .
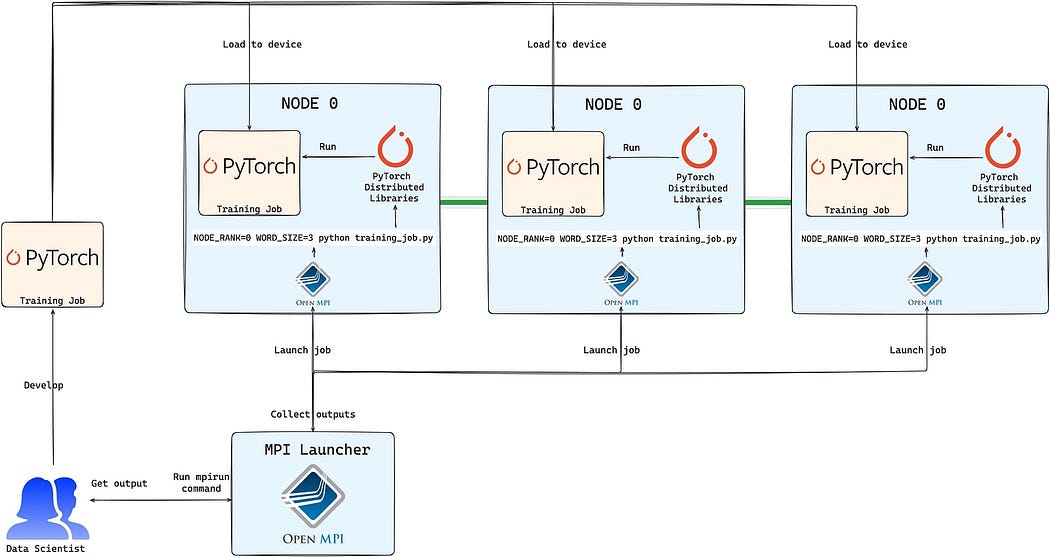
With the MPI launcher entity, the user does not have to run the launch command and manage the rank on each node separately
- Over SSH : this is one of the most popular ways to run the MPI job. A passwordless SSH connection must be set up for the workers, and the key must be managed with the launcher. The run trigger is performed manually on the launcher. This approach will be used for the demo.
- Over workload schedulers like Slurm or LSF : with these, we are talking about the most popular schedulers for managing distributed, batch-oriented HPC jobs and running diverse, finite, distributed workloads with flexible resource sharing. Setting up a Slurm or LFS cluster is a topic for its dedicated article. Still, in a nutshell, the purpose of these schedulers is mostly managing a job queue and spawning containerized workloads (although it is not LSF's initial purpose). Slurm and LFS are, however, designed for different problems.
To run an mpirun job , each node must have a compatible MPI runtime installed, with only the worker nodes requiring the same training code and libraries loaded into their runtime environments and an available and running SSH daemon. The launcher node typically does not perform any workload tasks, so it requires minimal resources and does not need workload-specific libraries but the command, among others, requires the worker hostnames and number of processes to spawn as parameters. When using the MPI collectives backend, frameworks like Horovod can simplify implementation, but for standard usage, experiment code must be adapted to use the MPI (in this case, OpenMPI) environment job variables instead of those provided by torchrun:
Launching PyTorch training job with MPI launcher over SSH on 3 nodes (2x AWS EC2 T3.xlarge as workers and 1x AWS EC2 T3.micro as launcher)
Ray
Ray is a distributed computing framework designed to simplify machine learning workflows by abstracting away much of the complexity of resource management and process coordination. Unlike torchrun and mpirun, which focuses heavily on static configurations and explicit job launching, Ray provides a more dynamic and fault-tolerant approach to distributed training.

However, Ray’s elastic collectives configuration lacks some of the fine-grained control and efficiency of MPI and torchrun, particularly for large-scale, tightly coupled training jobs where low-latency communication between nodes is essential. While Ray implements Gloo and NCCL collective backends , its abstractions can introduce additional overhead, making it less performant for high-throughput workloads already optimized using bare collective backends such as Gloo, MPI, UCC, or NCCL.
Ray is a good fit for moderate-scale clusters when workflows demand fault tolerance, or integration with broader tasks like hyperparameter tuning or distributed preprocessing. It excels in scenarios where node failure is expected, workloads are dynamic, and resource demands vary across tasks. However, for purely training-focused pipelines with tightly controlled environments, torchrun or mpirun may still be more efficient choices.
Running distributed training with Ray is fairly easy when the nodes are configured to join the same Ray Cluster , typically by running the Ray runtime on each node and connecting them to a shared head node. The code also has to use Ray wrappers on top of the model and dataset to allow collective management:
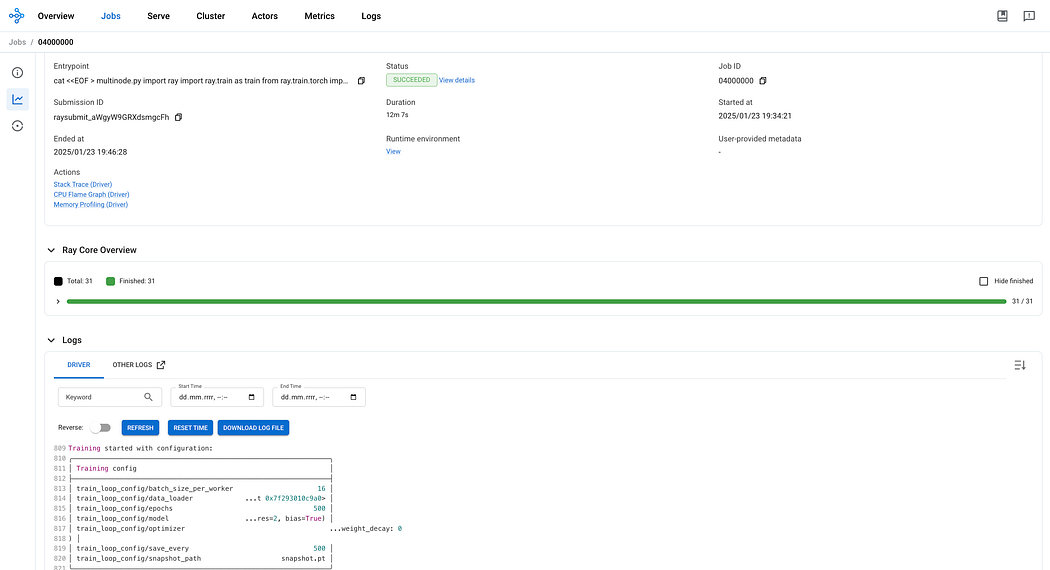
Ray Dashboard with distributed job details
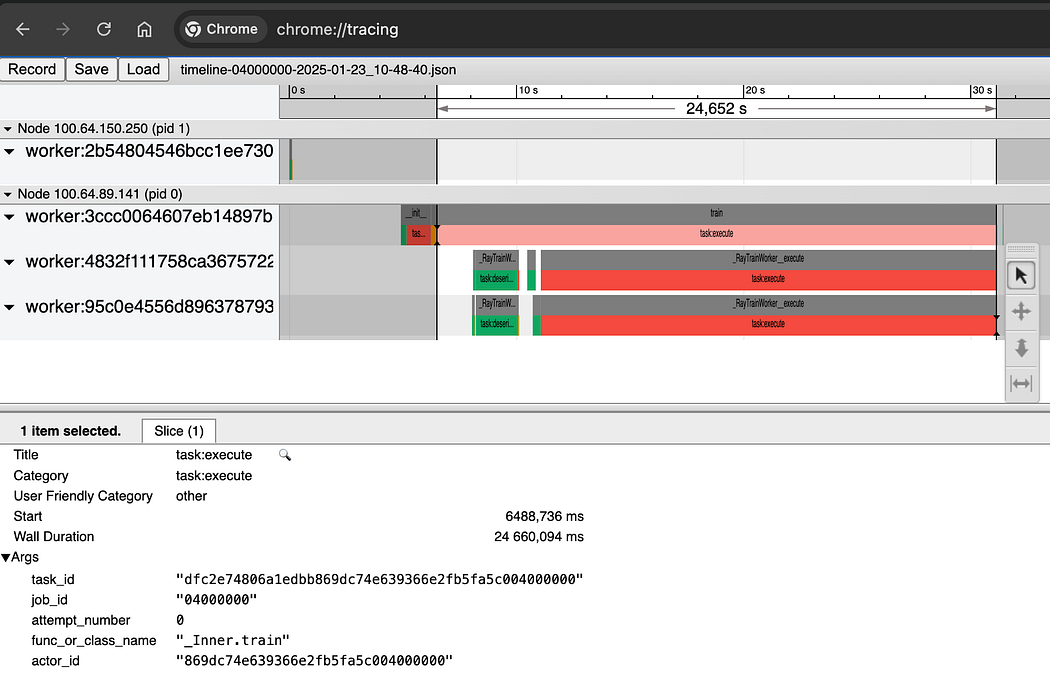
A neat feature of Ray — job trace output
Moderate-scale clusters and HPC systems bridge the gap between single-node experiments and enterprise-level infrastructure, offering teams the flexibility to scale without overwhelming complexity. By adopting tools like MPI or Ray, organizations unlock faster, better-configured training cycles, support larger models, and manage multiple experiments simultaneously. Whether fine-tuning a vision transformer on a cloud cluster or parallelizing genomic analysis across on-premise nodes, these implementations empower teams to tackle efficiently challenges that single machines cannot handle.
Large and Enterprise-size clusters
Models and datasets are not the only entities that grow and expand. In enterprise environments, organizations often support multiple teams, each developing diverse products, from recommendation systems and fraud detection models to real-time AI assistants, under one infrastructure umbrella. Scaling efficiently here isn’t just about handling bigger models or data; it’s about enabling collaboration at scale while avoiding resource conflicts, bottlenecks, or wasted computing.
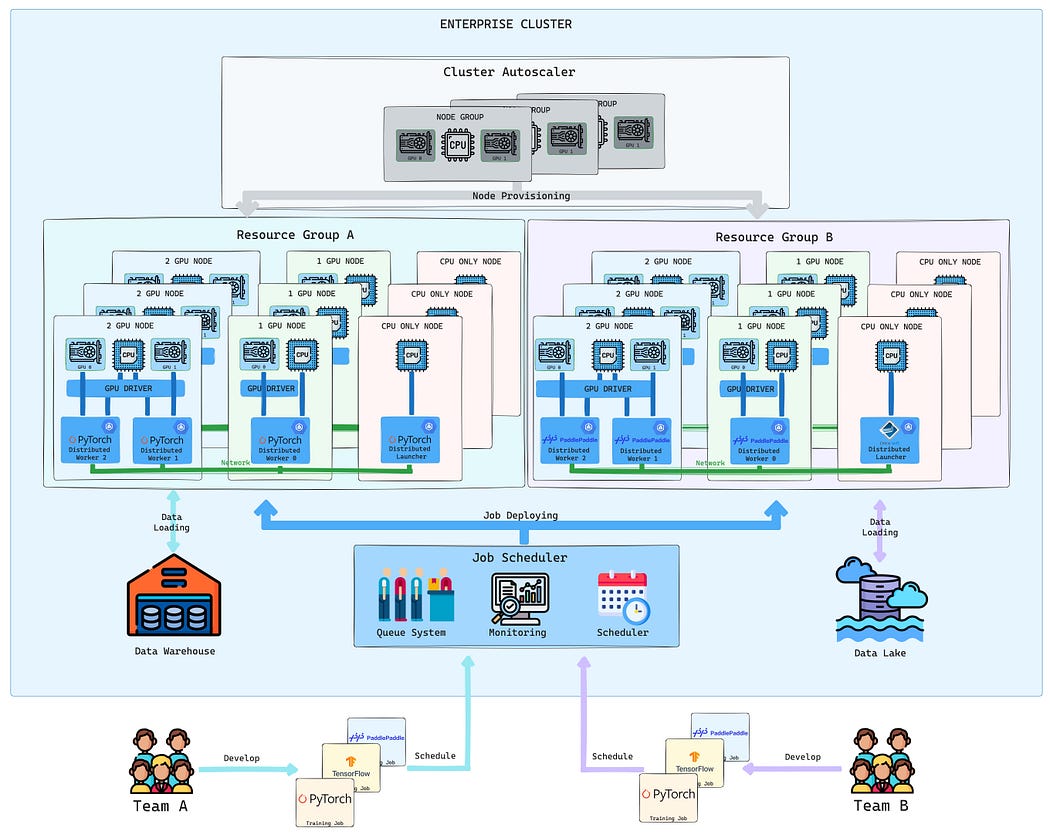
Enterprise-sized clusters efficiently utilize resources and enable multiple teams to run their training jobs simultaneously and securely
Large or enterprise-size clusters — spanning hundreds or thousands of devices — are designed to tackle this complexity. These setups power high-performance computing (HPC) workflows for internal teams, external customers, or both. However, their sheer scale introduces unique challenges:
- Resource management: Computing power is expensive. Scheduling a training job that requires many devices is not just about availability but also about efficient allocation. Large-scale clusters often operate with quotas, reservations, and priority-based scheduling. Over-provisioning wastes compute, while under-provisioning slows down experiments. Solutions include workload-aware schedulers that dynamically allocate resources based on job needs and queue conditions.
- Queue management: As multiple teams and users submit jobs, fair scheduling and prioritization become key. A queuing system must balance short, exploratory jobs with long-running training workloads. Some solutions include preemptible jobs, dynamic priority adjustments, and enforcing SLAs per user or department.
- Storage: Distributed jobs require high-throughput, low-latency storage, especially when frequently shuffling large datasets or checkpointing. Ceph, while scalable, may introduce latency overhead for high-performance applications. Alternatives like Dell’s PowerFlex offer high IOPS, low-latency access, and deep integration with containerized workloads through CSI drivers, making it a strong choice for high-throughput data pipelines and model checkpointing.
- User management and tenant separation: Enterprise clusters support multiple teams with different requirements and permissions. Isolating workloads, ensuring fair resource usage, and maintaining security boundaries are crucial. Role-based access control (RBAC), namespace isolation (e.g., Kubernetes or Slurm partitions), and per-tenant quotas help enforce these boundaries while allowing efficient cluster utilization that translates into cost savings.
Given the scale and complexity of enterprise clusters, Kubernetes is often a strong choice due to its built-in orchestration, scheduling flexibility, and ecosystem support for distributed computing frameworks. While not the only option, its ability to manage resources dynamically, support heterogeneous workloads, and integrate with modern storage and networking solutions makes it well-suited for large-scale distributed ML workflows. Additionally, several solutions simplify launching distributed jobs with familiar mechanisms, making deployment more convenient:
Being used to launching distributed training jobs with torchrun or mpirun, the Kubeflow Training Operator is a good choice for scaling up. It implements an operator framework for managing distributed ML workloads in Kubernetes, providing CRDs that abstract the complexity of managing multi-node training jobs. It can be deployed as a standalone controller or integrated with the Kubeflow SDK .
How to build and share components for Kubeflow Pipelines
Building Kubeflow Pipelines components is a great way to encapsulate your code and share it with others. Let’s build…
It supports frameworks like PyTorch, TensorFlow, XGBoost and MPI launchers, providing workload-specific configurations for resource allocation, checkpointing, and fault tolerance:
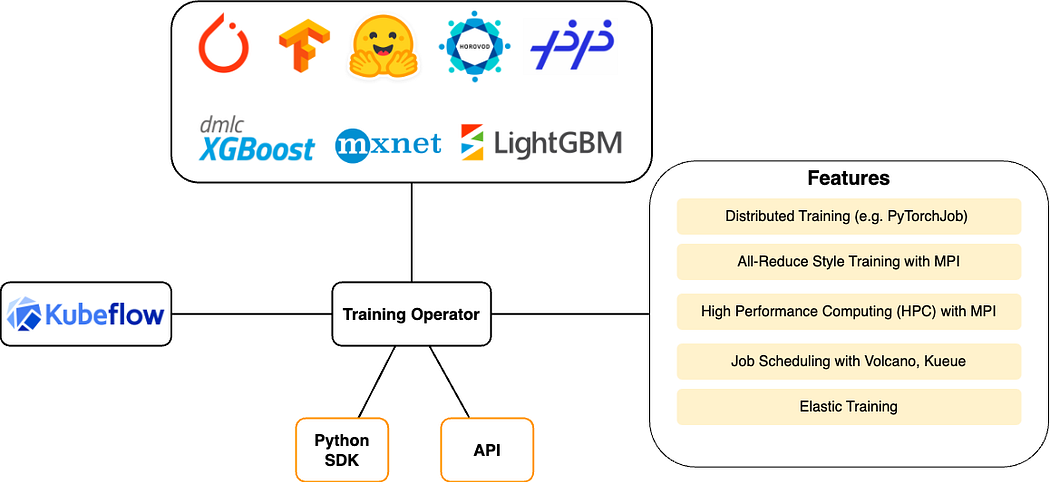
To launch a job, users define a CRD (e.g., PyTorchJob or TFJob) manifest , specifying worker configurations, resource limits, and training parameters. The Training Operator then schedules, monitors, and manages the lifecycle of the training job, including automatic restarts and fault tolerance:
— PyTorchJob
PyTorchJob provides elastic training capabilities and supports running the torchrun launcher. The manifest defines the Master and Worker sections, allowing each to be configured like regular pods regarding resource usage and container images. The resource automatically provisions parameters such as the number of workers, processes per worker, each worker's rank, and the rendezvous endpoint address.

The only requirement for the user is to specify the script parameters. All other prerequisites for running the PyTorch Elastic Launcher, such as compatible libraries and code availability (which can be managed via ConfigMap), must still be met on both the workers and the master node:
Launching a distributed PyTorchJob with 1 Master and 2 Workers on AWS EKS with training code loading using ConfigMap
Similar to the PyTorchJob, the MPIJob CRD enables launching distributed mpirun jobs on a Kubernetes cluster. Its key advantage over PyTorch’s torchrun is that it strictly separates Launcher pods from Worker pods. This distinction allows the Launcher to request fewer resources and only require the MPI runtime to be installed, making it more flexible and easier to schedule across nearly any available node in the cluster.
At this point, the MPIJob CRD is provided by the MPI Operator, which is still in the beta state and needs to be provisioned separately .
When launching a distributed experiment with the MPIJob , all the conditions apply like for a normal mpirun job, but the operator populates the Launcher with MPI-specific hosts in the /etc/mpi/hostfile ConfigMap mount. This can be used when defining the launch command:
The drawback is that when waiting for available Worker pods service hosts, the Launcher goes into a CrashLoopBackoff until a successful SSH connection is available:
Launching a distributed MPIJob with 3 Workers on AWS EKS with training code loading using ConfigMap
The Training Operator includes built-in support for tracking and monitoring job metrics through Prometheus and Grafana.
Enterprise-level Kubernetes clusters face critical challenges when managing large-scale distributed workloads, such as large ML training, big data processing, and real-time inference. Traditional scheduling methods, which handle pods individually, often lead to resource fragmentation and deadlocks when jobs require all-or-nothing execution — like training a 100B-parameter model where partial worker allocation stalls the entire task24. Gang scheduling addresses this by ensuring interdependent pods (e.g., distributed training workers) are either all scheduled simultaneously or not at all, eliminating wasted resources and preventing cascading failures.
In high-demand environments, clusters must balance competing priorities: short-lived experiments vs. long-running jobs, multi-team resource quotas, and cost-efficient hardware utilization. Without gang scheduling, partial pod allocation can block cluster throughput, while priority inversion — where low-priority tasks hog resources — stalls critical workflows.
Volcano enhances Kubernetes’ scheduling capabilities by introducing queue-based scheduling, job preemption, and gang scheduling.
Gang scheduling coordinates resource allocation by ensuring all resources needed for a distributed job are available before execution begins, preventing partial deployments across an incomplete set of nodes. This approach minimizes resource fragmentation and enables synchronized execution across multiple devices. Both Training Operator and KubeRay have the option to integrate with Volcano’s gang scheduling capabilities.
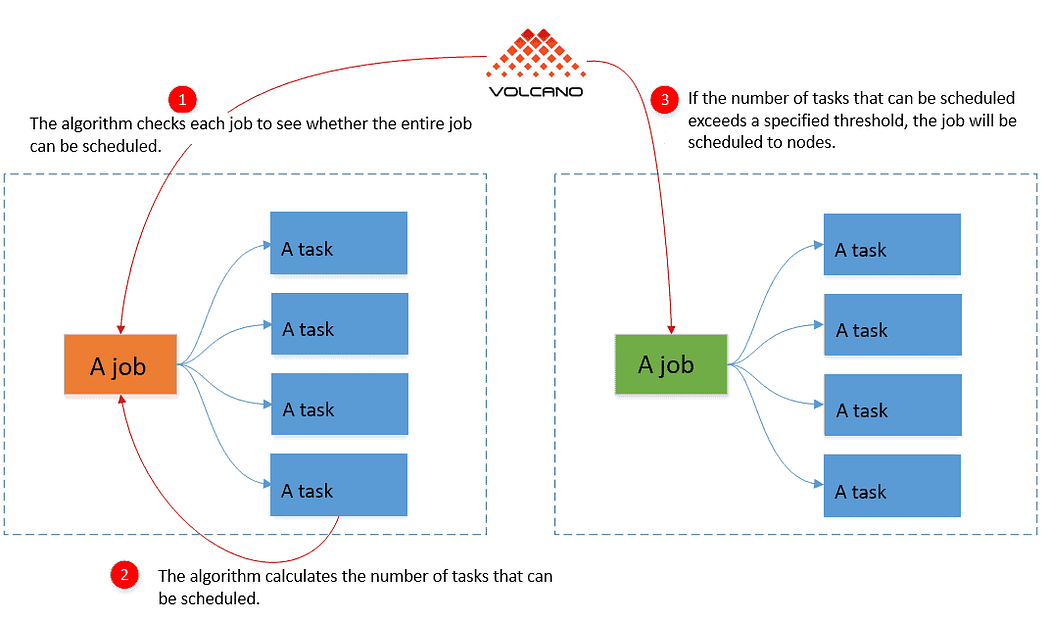
When implemented alongside cluster autoscalers such as Karpenter in EKS environments, gang scheduling can present operational challenges. If the autoscaler attempts to provision nodes with varying sizes or initialization times simultaneously, it may misinterpret waiting nodes as underutilized resources. This can trigger node deprovisioning, potentially creating a boot-loop scenario where jobs repeatedly fail to initialize. To address these issues, careful configuration of the autoscaler’s provisioning timeouts, scheduling policies and node pool labeling becomes essential.
The Volcano scheduler provides greater flexibility in configuration , including support for specifying multiple worker types. This makes it especially well-suited for workloads operating in heterogeneous device environments.

Launching a VolcanoJob to schedule a distributed MPI process with 2 Workers on AWS EKS with training code loading using ConfigMap
In conclusion, integrating Volcano Scheduler and gang scheduling into Kubernetes clusters represents a significant advancement in managing large-scale distributed workloads. As we continue to push the boundaries of machine learning and big data processing, these advanced scheduling techniques will be essential in maintaining efficient and reliable operations, ultimately driving innovation and performance in enterprise-level applications.
The KubeRay Operator integrates Ray clusters into Kubernetes environments by leveraging Custom Resource Definitions (CRDs) to manage cluster lifecycle, scaling, and resource allocation. Users define RayCluster objects in YAML to specify head and worker node configurations — including resource quotas, autoscaling rules, and environment variables — allowing Kubernetes to handle pod scheduling, health checks, and node recovery.
For enterprises, KubeRay simplifies integrating Ray with centralized logging (e.g., Fluentd), monitoring (Prometheus exporters for Ray metrics), and storage (CSI drivers for shared datasets). Its value lies in unifying distributed training with broader Kubernetes orchestration — such as running Ray alongside Spark jobs or inference servers — without introducing bespoke infrastructure. However, frameworks like torchrun or MPI might still outperform KubeRay in dedicated HPC clusters where low-level network tuning is prioritized over operational flexibility.
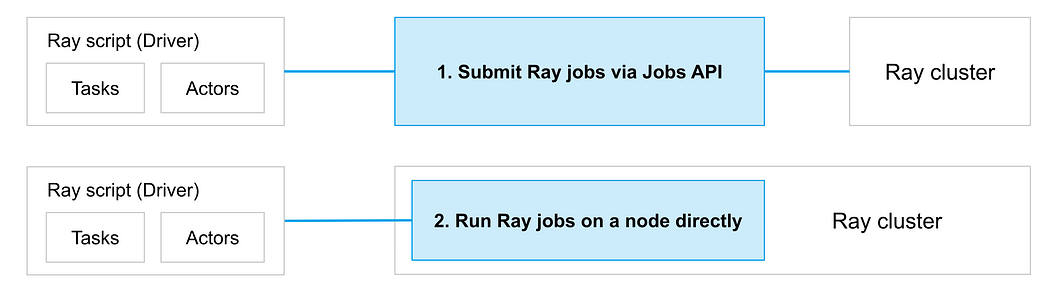
Currently, there are two ways of submitting distributed Ray Training jobs to a Ray Cluster:
- Submitting locally developed applications to a remote Ray Cluster via Ray Jobs API for execution. It simplifies the experience of packaging, deploying, and managing a Ray application.
- Running the script directly on a cluster node (e.g. after SSHing into the node using ray attach ), or use Ray Client to run a script from your local machine while maintaining a connection to the cluster.
Vendor solutions
The complexities of building and managing a custom distributed environment — dealing with intricate resource allocation, fault tolerance, and network communication challenges — often outweigh the benefits. Consequently, many organizations turn to vendor-provided solutions that abstract much of this operational burden. These platforms deliver prebuilt orchestration, auto-scaling, and monitoring tools that enable teams to focus on model development and experimentation, rather than the underlying infrastructure.
Vendor solutions abstract much of the operational complexity involved in distributed workloads, offering prebuilt orchestration, resource scaling, and monitoring tools. While they simplify deployment, they often come with high costs and restricted configuration options, making them less flexible than a fully custom Kubernetes setup.
- Run:ai : Optimized for AI/ML workloads, Run:ai dynamically allocates available computing resources, minimizing idle time and improving utilization. A key feature is workload pausing and resumption, which helps balance competing jobs and ensures high-priority tasks get scheduled first. Run:ai also provides auto-scaling and job prioritization, making it useful for teams running experiments on shared compute clusters.
- Public Cloud Solutions ( AWS SageMaker , Google Vertex AI , and A zure ML ): These platforms provide fully managed distributed training environments with built-in support for provisioning, scaling, and monitoring. They integrate with cloud-native storage and networking as well as abstractions on top of available distribution strategies, offloading infrastructure management from the user. However, they restrict configuration flexibility, limiting users to predefined instance types, environments, and auto-scaling policies. While they make training more accessible, costs can escalate quickly, especially for long-running or resource-intensive jobs.
- Databricks : Supports distributed training through DeepSpeed distributor, TorchDistributor, and Ray, providing multiple ways to scale ML workloads. While single-machine training is preferred when possible to minimize communication overhead, these distributed approaches become necessary for large models and datasets. DeepSpeed distributor is optimized for memory-constrained scenarios, using pipeline parallelism and efficient memory allocation. TorchDistributor integrates PyTorch with Spark clusters, handling worker communication and environment setup. Databricks also incorporates Ray for parallel compute workflows and supports Spark ML distributed training through pyspark.ml.connect. While Databricks simplifies distributed ML, users trade off fine-grained infrastructure control for a more streamlined experience.
Fault tolerance
In distributed machine learning, one of the biggest challenges is handling node or network failures during training. Imagine you have a training job that has been running uninterrupted for two months — only to have one worker node drop unexpectedly. Such failures, whether caused by hardware crashes, network partitions, or storage errors, can break the synchronization needed for gradient aggregation or even corrupt checkpoints. As a result, valuable compute time may be wasted and manual intervention might be needed to restart the process.
If a worker node drops, the impact depends heavily on the distribution strategy. Parameter server models tend to be more resilient, as updates occur asynchronously, meaning, that losing a worker won’t necessarily stop training — unless the number of failures crosses a critical threshold.
In contrast, collective all-reduce strategies (common in frameworks like PyTorch DDP or MPI) rely on tight synchronization between all nodes. A single failure can stall the entire process, making recovery difficult without restarting from a checkpoint.
Improving fault tolerance comes down to two core strategies:
- Checkpointing with reliable storage: Checkpoints must be saved to a backend that persists beyond node failures (e.g., AWS S3, GCS, MinIO, or Ceph), ensuring that jobs can resume from the last saved state rather than starting from scratch.
- Retry and restart policies: Some failures can be mitigated at the orchestration level by enabling job retries at the launcher (e.g., Kubernetes restartPolicy: OnFailure or Slurm job retries). In more advanced cases, frameworks like TorchElastic or Ray Tune can detect failures and dynamically reschedule workers to maintain job progress, though this adds overhead.
Even with robust fault-tolerant strategies, early failure detection and root cause analysis are critical to minimizing downtime. Monitoring systems track node health, job progress, and failure patterns, helping teams pinpoint recurring issues. Kubernetes-native solutions like Prometheus + Grafana (for metrics) and Fluentd or Loki (for logs) provide insights into node failures, memory leaks, or network bottlenecks.
Distributed training systems can remain resilient even in large-scale environments by combining monitoring, scheduling, checkpointing, and adaptive failure recovery.
Summary
Wrapping up our journey into distributed processing in machine learning, it’s clear that distributed training is more of a revolution. By breaking away from the limitations of single-device computing, distributed strategies empower organizations to train models that were once considered out of reach. Imagine reducing a training task from hypothetical centuries to mere days, or even hours, by harnessing the collective power of multiple GPUs and nodes. That’s the transformative impact of distributed ML.
Throughout this article, we’ve explored how various strategies — data parallelism, tensor parallelism, pipeline parallelism, and even hybrid methods — address the unique challenges of enormous datasets and ever-growing model architectures. Each approach plays its part:
- Data Parallelism splits large datasets across devices, ensuring every processor works simultaneously on a portion of the data.
- Tensor and Pipeline Parallelism divide models and their layers so that even colossal architectures can be trained without hitting memory limits.
Implementations on local workstations, moderate clusters, or large-scale enterprise systems show that the right configuration is key. Well-configured clusters deliver dramatic speed-ups and scalability and contribute to cost savings. Whether you’re orchestrating jobs with tools like torchrun, MPI, or Kubernetes — and leveraging fault tolerance with checkpointing and automated retries — these solutions pave the way for resource efficiency and rapid innovation.
At its core, distributed processing is about collaboration — each node, each device, sharing a part of the workload to build models that power tomorrow’s breakthroughs. By leveraging the right strategies, organizations can train faster, scale smarter, and reduce infrastructure costs, unlocking new opportunities in AI-driven innovation.
Dive in
Related
Blog
Distributed Training in MLOps: How to Efficiently Use GPUs for Distributed Machine Learning in MLOps
By Rafał Siwek • Mar 19th, 2025 • Views 669
Blog
Bag of Tricks for Optimizing Machine Learning Training Pipelines
By Arseny Kravchenko • Jan 13th, 2023 • Views 293
Blog
Distributed Training in MLOps Break GPU Vendor Lock-In: Distributed MLOps across mixed AMD and NVIDIA Clusters
By Rafał Siwek • Apr 7th, 2025 • Views 327
Blog
Distributed Training in MLOps: How to Efficiently Use GPUs for Distributed Machine Learning in MLOps
By Rafał Siwek • Mar 19th, 2025 • Views 669
Blog
Distributed Training in MLOps Break GPU Vendor Lock-In: Distributed MLOps across mixed AMD and NVIDIA Clusters
By Rafał Siwek • Apr 7th, 2025 • Views 327
Blog
Bag of Tricks for Optimizing Machine Learning Training Pipelines
By Arseny Kravchenko • Jan 13th, 2023 • Views 293