
GraphRAG Analysis, Part 2: Graph Creation and Retrieval vs Vector Database Retrieval

# GraphRAG
# Retrieval Database
# Vector Database
# The Objective AI
GraphRAG increases faithfulness but not other RAGAS metrics, and the ROI of knowledge graphs may not justify the hype
August 29, 2024
Jonathan Bennion
TLDR:
GraphRAG (when fully created and retrieved in Neo4j via Cypher) enhances faithfulness (a RAGAS metric that is similar to precision - e.g. does it accurately reflect the information in the RAG document) over vector-based RAG, but does not effect other RAGAS metrics. It may not offer enough ROI to justify the hype of the accuracy benefits given the performance overhead.
Implications (see list of potential biases in this analysis at bottom of post):
- Improved accuracy: GraphRAG could be beneficial in domains requiring high precision, such as medical or legal applications.
- Complex relationships: It may excel in scenarios involving intricate entity relationships, like analyzing social networks or supply chains.
- Trade-offs: The improved faithfulness comes at the cost of increased complexity in setup and maintenance of the knowledge graph, so the hype may not be justified.
Introduction:
This post is a follow up to GraphRAG Analysis Part 1, which performed RAG on the US Presidential Debate transcript between Biden and Trump (a document not in the training data of any model as of this blog post), comparing the vector db of Neo4j (a graph database) to the vector db of FAISS (a non-graph database). This allowed for a clean compare on the database, while in this post (being Part 2), the comparison incorporates knowledge graph creation and retrieval in Neo4j using cypher against the FAISS baseline to evaluate how these two approaches perform on RAGAS metrics for the same document.
Setting Up the Environment
First, let's set up our environment and import the necessary libraries:
Setting Up Neo4j Connection
To use Neo4j as the graph database, let's set up the connection and create some utility functions:
These functions help us manage our Neo4j database, ensuring we have a clean slate for each run and that our vector index is properly set up.
Data Processing and Graph Creation
Now, let's load our data and create our knowledge graph:
This approach uses GPT-3.5-Turbo to extract entities and relationships from our text, creating a dynamic knowledge graph based on the content of our document.
Setting Up Retrievers
We'll set up two types of retrievers: one using FAISS for vector-based retrieval, and another using Neo4j for graph-based retrieval.
The FAISS retriever uses vector similarity to find relevant information, while the Neo4j retrievers leverage the graph structure to find related entities and their relationships.
Creating RAG Chains
Now, let's create our RAG chains:
These chains associate the retrievers with a language model to generate answers based on the retrieved context.
Evaluation Setup
To evaluate our RAG systems, we'll create a ground truth dataset and use the RAGAS framework:
def create_ground_truth(texts: List[Union[str, Document]], num_questions: int = 100) -> List[Dict]: llm_ground_truth = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.2) def get_text(item): return item.page_content if isinstance(item, Document) else item text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) all_splits = text_splitter.split_text(' '.join(get_text(doc) for doc in texts)) ground_truth = [] question_prompt = ChatPromptTemplate.from_template( "Given the following text, generate {num_questions} diverse and specific questions that can be answered based on the information in the text. " "Provide the questions as a numbered list.\n\nText: {text}\n\nQuestions:" ) all_questions = [] for split in tqdm(all_splits, desc="Generating questions"): response = llm_ground_truth(question_prompt.format_messages(num_questions=3, text=split)) questions = response.content.strip().split('\n') all_questions.extend([q.split('. ', 1)[1] if '. ' in q else q for q in questions]) random.shuffle(all_questions) selected_questions = all_questions[:num_questions] llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) for question in tqdm(selected_questions, desc="Generating ground truth"): answer_prompt = ChatPromptTemplate.from_template( "Given the following question, provide a concise and accurate answer based on the information available. " "If the answer is not directly available, respond with 'Information not available in the given context.'\n\nQuestion: {question}\n\nAnswer:" ) answer_response = llm(answer_prompt.format_messages(question=question)) answer = answer_response.content.strip() context_prompt = ChatPromptTemplate.from_template( "Given the following question and answer, provide a brief, relevant context that supports this answer. " "If no relevant context is available, respond with 'No relevant context available.'\n\n" "Question: {question}\nAnswer: {answer}\n\nRelevant context:" ) context_response = llm(context_prompt.format_messages(question=question, answer=answer)) context = context_response.content.strip() ground_truth.append({ "question": question, "answer": answer, "context": context, }) return ground_truth
async def evaluate_rag_async(rag_chain, ground_truth, name): splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
generated_answers = [] for item in tqdm(ground_truth, desc=f"Evaluating {name}"): question = splitter.split_text(item["question"])[0]
try: answer = await rag_chain.ainvoke(question) except AttributeError: answer = rag_chain.invoke(question)
truncated_answer = splitter.split_text(str(answer))[0] truncated_context = splitter.split_text(item["context"])[0] truncated_ground_truth = splitter.split_text(item["answer"])[0]
generated_answers.append({ "question": question, "answer": truncated_answer, "contexts": [truncated_context], "ground_truth": truncated_ground_truth })
dataset = Dataset.from_pandas(pd.DataFrame(generated_answers))
result = evaluate( dataset, metrics=[ context_relevancy, faithfulness, answer_relevancy, context_recall, ] )
return {name: result}async def run_evaluations(rag_chains, ground_truth): results = {} for name, chain in rag_chains.items(): result = await evaluate_rag_async(chain, ground_truth, name) results.update(result) return results
# Main execution functionasync def main(): # Ensure vector index ensure_vector_index(recreate=True) # Create retrievers neo4j_retriever = create_neo4j_retriever() # Create RAG chains faiss_rag_chain = create_rag_chain(faiss_retriever) neo4j_rag_chain = create_rag_chain(neo4j_retriever) # Generate ground truth ground_truth = create_ground_truth(texts) # Run evaluations rag_chains = { "FAISS": faiss_rag_chain, "Neo4j": neo4j_rag_chain } results = await run_evaluations(rag_chains, ground_truth) return results
# Run the main functionif __name__ == "__main__": nest_asyncio.apply() try: results = asyncio.run(asyncio.wait_for(main(), timeout=7200)) # 2 hour timeout plot_results(results) # Print detailed results for name, result in results.items(): print(f"Results for {name}:") print(result) print() except asyncio.TimeoutError: print("Evaluation timed out after 2 hours.") finally: # Close the Neo4j driver driver.close()This setup creates a ground truth dataset, evaluates our RAG chains using RAGAS metrics, and visualizes the results.
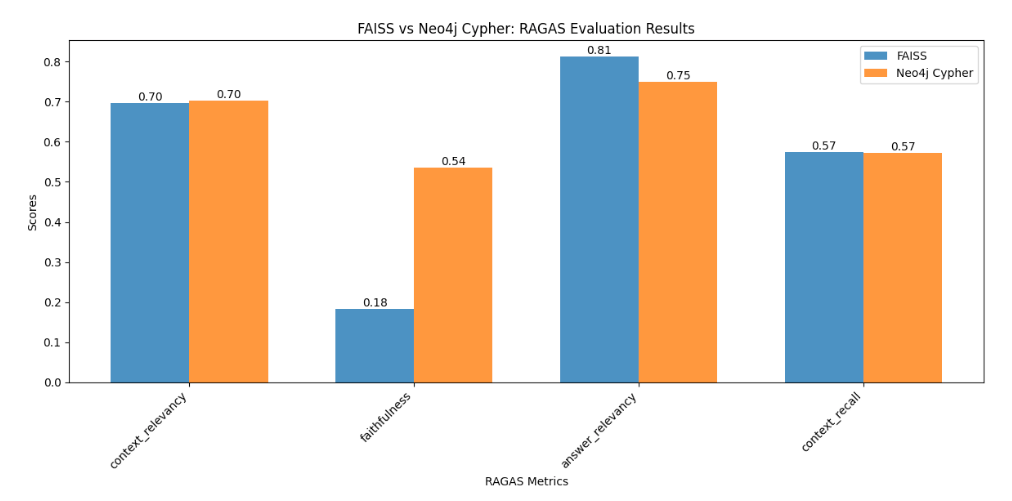
Results and Analysis
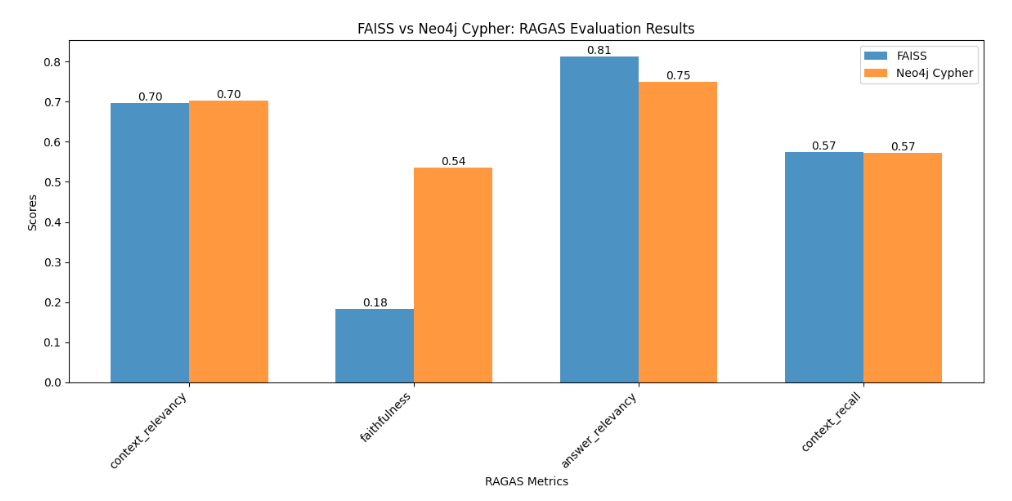
This analysis revealed a surprising similarity in performance between GraphRAG and vector-based RAG across most metrics, with one difference:
- Faithfulness:
- Neo4j GraphRAG significantly outperformed FAISS (0.54 vs 0.18)
The graph-based approach excels in faithfulness likely because it preserves the relational context of information. When retrieving information, it can follow the explicit relationships between entities, ensuring that the retrieved context is more closely aligned with the original structure of the information in the document.
Implications and Use Cases
While the overall performance similarity suggests that for many applications, the choice between graph-based and vector-based RAG may not significantly impact results, there are specific scenarios where GraphRAG's advantage in faithfulness could be crucial:
- Faithfulness-critical applications: In domains where maintaining exact relationships and context is crucial (e.g., legal or medical fields), GraphRAG could provide significant benefits.
- Complex relationship queries: For scenarios involving intricate connections between entities (e.g., investigating financial networks or analyzing social relationships), GraphRAG's ability to traverse relationships could be advantageous.
- Maintenance and updates: Vector-based systems like FAISS may be easier to maintain and update, especially for frequently changing datasets.
- Computational resources: The similar performance in most metrics suggests that the additional complexity of setting up and maintaining a graph database may not always be justified, depending on the specific use case and available resources.
Note on Potential Biases:
- Knowledge graph creation: The graph structure is created using GPT-3.5-Turbo, which may introduce its own biases or inconsistencies in how entities and relationships are extracted.
- Retrieval methods: The FAISS retriever uses vector similarity search, while the Neo4j retriever uses a Cypher query. These fundamentally different approaches may favor certain types of queries or information structures, but this is what is being evaluated.
- Context window limitations: Both methods use a fixed context window size, which may not capture the full complexity of the knowledge graph structure if anything different is required.
- Dataset specificity: Overall (and this is a given in 100% of all AI tool analysis): the analysis is performed on a single document (debate transcript), which may not be representative of all potential use cases.
Originally posted at:
Dive in
Related
Blog
Should You Use Graph-based Vector Database for Multimodal AI?
By Sonam Gupta • May 22nd, 2025 • Views 142
Blog
Automating Knowledge Graph Creation with Gemini and ApertureDB - Part 2
By Ayesha Imran • Aug 5th, 2025 • Views 142
Blog
Automating Knowledge Graph Creation with Gemini and ApertureDB - Part 1
By Ayesha Imran • Jul 30th, 2025 • Views 174
Blog
Should You Use Graph-based Vector Database for Multimodal AI?
By Sonam Gupta • May 22nd, 2025 • Views 142
Blog
Automating Knowledge Graph Creation with Gemini and ApertureDB - Part 2
By Ayesha Imran • Aug 5th, 2025 • Views 142
Blog
Automating Knowledge Graph Creation with Gemini and ApertureDB - Part 1
By Ayesha Imran • Jul 30th, 2025 • Views 174