
The Impact of Prompt Bloat on LLM Output Quality

# LLMs
# Prompt Bloat
# Machine Learning
How irrelevant information degrades LLM performance and what to do about it
July 15, 2025
Soham Chatterjee
The quality of the prompts supplied to LLMs directly influences the accuracy and relevance of generated outputs. A big challenge in prompt engineering is irrelevant or excessive information in prompts, particularly in the context.
In this blog, we will look at the effects of irrelevant prompt inputs on the quality and correctness of LLM outputs and looking at techniques, both automated and manual, to refine and optimize prompts by removing unnecessary information. Understanding this is crucial for AI developers to maximize the performance and reliability of LLMs in production apps.
The Influence of Prompt Length on LLM Output
The length of a prompt plays a crucial role in determining the quality of an LLM's response. Short, zero-shot prompts don’t provide all the necessary information for the LLM to understand the task and follow directions, leading to low-quality outputs.
A solution to this has been to provide LLMs with a lot of context and examples. Unfortunately, this, along with the increasing context length of LLMs, has led to AI developers dumping entire websites, books, and internal knowledge bases into every prompt in an attempt to supply LLMs with all the necessary information.
Excessively long prompts can introduce complexity and confusion, potentially causing the model to lose focus or misinterpret the core request. The ideal length is not absolute but rather depends on factors such as the complexity of the task, the specific goal of the prompt, and the capabilities of the particular LLM being used.
For instance, simple queries typically require shorter prompts, while more intricate tasks require longer prompts to establish the necessary context. However, it is essential to note that longer prompts do not lead to better results and can become counterproductive if they contain irrelevant or poorly structured information.
Even with the large token limits of newer AI models, a "lost in the middle" effect can occur with long prompts. This is the tendency of LLMs to give less weight to information located in the middle of a long context compared to the information at the beginning or end.
For example, in a debugging scenario with extensive log files, an LLM might focus on the initial error messages and overlook a more critical exception located later in the sequence. This means that staying within the token limit is not sufficient; the distribution and placement of crucial information within the prompt are also key for effective processing of prompts.
Researchers have also demonstrated that increasing input length can negatively impact the reasoning capabilities of LLMs, even at lengths significantly shorter than their technical maximum [1]. A paper by Goldber et. al. [1] found a degradation in reasoning performance of LLMs at around 3000 tokens, well below the context windows of LLMs. This shows that there is a limit to the length of a prompt beyond which performance starts to decline.
They also show that even techniques like Chain-of-Thought (CoT) prompting, which are designed to enhance reasoning by encouraging step-by-step thinking, do not lower this degradation when inputs become excessively long.
This indicates that the challenge of processing and reasoning over long sequences is a fundamental limitation that prompt engineering techniques can only partially address.
Degradation of LLM Output Quality Due to Extraneous Information
Beyond the impact of length, the inclusion of irrelevant or extra information in prompts can also significantly degrade the quality of LLM outputs. Researchers have shown that LLMs can be easily distracted by such irrelevant context, leading to less accurate and less relevant responses [2]. This is also true for humans, where irrelevant information has been shown to decrease problem-solving accuracy [2].
Even a seemingly small amount of irrelevant information within a prompt can lead to inconsistent predictions and a notable decline in the model's performance on the intended task [2]. This vulnerability to "noise" in the input highlights a key limitation in the current generation of LLMs, as they can struggle to effectively filter out extraneous details and focus on the core information required for accurate processing of the actual task.
The presence of extraneous information impacts the quality metrics of LLM outputs, including coherence, relevance, and factual correctness. When an LLM is given irrelevant details, its attention mechanisms might be diverted, leading it to generate responses that are off-topic or lack a clear focus. Furthermore, the inclusion of unnecessary information can sometimes cause the model to misinterpret the prompt, potentially resulting in responses that contain factual errors or lack consistency.
A significant challenge identified in research is the "identification without exclusion" problem [3]. Research shows that while LLMs often possess the capability to identify irrelevant details within a prompt, they struggle to ignore this information during the response generation process.
This means that even if the model can recognize certain parts of the input as not important to the task, these irrelevant details can still influence the output, leading to inaccuracies or distractions. This limitation shows the need for methods that not only identify but also actively filter out irrelevant information from prompts before sending them to an LLM to generate the final response.
This is especially alarming since LLMs have been shown to be more vulnerable to noisy inputs in reasoning and chain-of-thought prompting, two of the most popular prompting techniques today [4]. Noisy inputs within the prompt that also leads to inaccurate reasoning steps.
This shows the importance of ensuring the quality and relevance in all parts of the prompt, including any examples or guidelines provided to guide the model's reasoning process. Even subtle noise within these elements can have a detrimental impact on the LLM's ability to reason correctly.
Beyond irrelevant context, other forms of input imperfections, such as grammatical mistakes and spelling errors can also negatively affect LLM performance, however the impact is not as much as irrelevant context. Research shows that LLMs exhibit resilience to certain types of noise, such as grammatical errors that might be present in their training data [5].
The Impact of Different Types of Irrelevant Information
Researchers have also found that the kind of irrelevant information plays a crucial role in its impact on LLM performance. LLMs are more vulnerable to irrelevant information that is semantically similar to the task at hand compared to information that is unrelated [6].
This type of semantically related but irrelevant information can be more misleading for LLMs, as they may struggle to distinguish it from genuinely relevant context due to the overlap of concepts. This suggests that the degree of semantic overlap between irrelevant information and the core task influences the extent to which the LLM is negatively affected, with closer semantic ties posing a greater challenge to the model's ability to accurately discern and process information.
For example, if a prompt asks for a summary of a news article about climate change, including irrelevant information about a different environmental issue might be more confusing than including information about a sports event. This is because the semantic overlap can mislead the LLM.
Including contradictory statements within a prompt can severely impact the LLM's ability to generate the correct response. For instance, if a prompt mentions that "the tennis ball is green" and later says "the tennis ball is blue," the model might produce an output that shows this confusion or makes an incorrect assertion.
The inclusion of information about entirely unrelated topics can also distract the LLM and lead to irrelevant or off-topic responses. While this is less damaging than semantically related or contradictory information, these unrelated details introduce noise that can still shift the model's focus away from the core task.
Measuring the Impact of Irrelevant Information in your Prompts
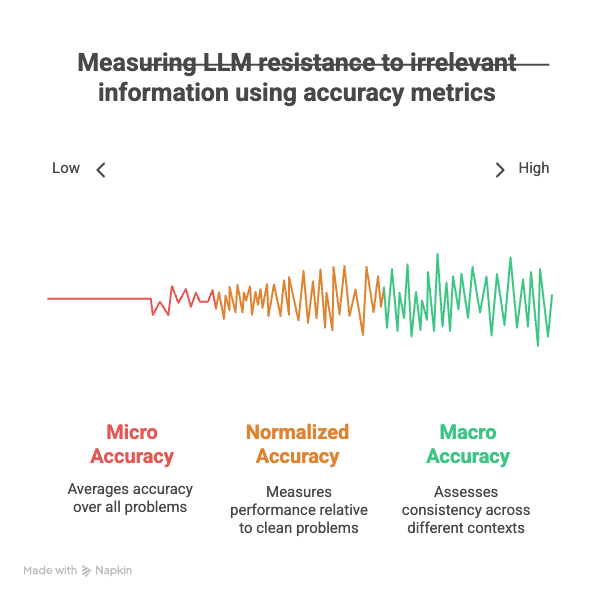
Researchers have employed specific metrics to objectively measure the extent to which irrelevant context can affect LLM performance. One such dataset, Grade-School Math with Irrelevant Context (GSM-IC), derived from the GSM8K dataset by adding irrelevant sentences to math problems, has been used to evaluate the distractibility of LLMs.
The impact is quantified using metrics such as micro accuracy, which represents the average accuracy over all test problems, and macro accuracy, which assesses the consistency of the model's performance across different irrelevant contexts added to the same original problem. Additionally, normalized accuracy is used to measure how the presence of distractors affects a method's performance relative to its performance on the original, clean problems. These metrics provide a quantitative framework for assessing the susceptibility of LLMs to irrelevant information.
Automatic Techniques for Prompt Cleaning and Optimization
Various automatic techniques have been developed for cleaning and optimizing prompts. Text summarization techniques can be used to condense long input prompts, potentially removing redundant or less critical information while retaining the essential context. This can lead to more focused prompts that are less likely to confuse the LLM.
Keyword extraction algorithms can identify the most salient terms within a prompt, and the prompt can then be reformulated using these keywords to create a more concise and targeted instruction. You can also use models to identify redundancies and remove repetitive phrases or sentences within a prompt.
More advanced AI-driven prompt optimization techniques have also come about. Meta Prompting involves using another language model to analyze and refine the original prompt, identifying patterns in successful and unsuccessful prompts to generate an improved version. Gradient Prompt Optimization treats prompts as parameters that can be optimized using gradient-based methods to enhance performance based on predefined metrics.
Frameworks like DSPy automate the prompt optimization process by integrating various techniques, including the dynamic generation of few-shot examples and Bayesian search strategies to find the most effective prompt structures. Other frameworks, such as ScaleDown, scan your prompt for irrelevant context and remove those tokens from your prompt. This increases accuracy while reducing latency and costs by lowering token usage. Bayesian Optimization has also been explored as a method for efficiently searching the prompt space to find optimal prompts that maximize performance on a given task.
Prompt chaining is another effective strategy that involves breaking down complex tasks into a sequence of smaller, more manageable prompts. The output of one prompt in the chain serves as the input for the next, allowing for a step-by-step approach to complex problem-solving.
Automatic Versus Manual Prompt Optimization and Cleaning
While manual prompt construction might help create effective prompts, the reality is that many organizations need to process thousands of prompts daily across multiple AI applications. Automatic methods are more efficient and scalable, making them well-suited for handling a large volume of prompts where manual prompt cleaning, especially for dynamically generated context, would be impossible.
Human experts can apply domain-specific knowledge to identify subtle irrelevant context that automatic methods might miss. The effectiveness of automatic versus manual cleaning can also depend on the complexity of the task and the nature of the irrelevant information. Highly complex or nuanced cases might still need humans in the loop to ensure that the prompt is compressed without losing crucial context.
Frameworks for Effective Prompt Construction
A good prompt should have clarity, specificity, and context. Prompts should be clear in their intent, specific in their instructions, and provide sufficient context for the LLM to understand the task.
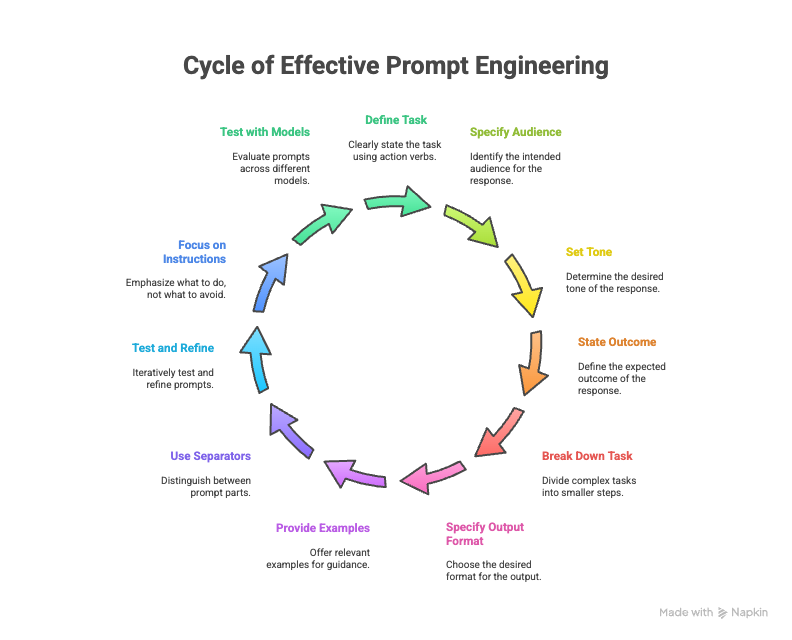
Here are some tips for writing good prompts:
Start with direct instructions using action verbs to clearly define the task.
Clearly specify the intended audience, desired tone, and expected outcome of the response.
For complex tasks, break them down into smaller, more manageable steps.
Explicitly state the desired output format, whether it be a list, paragraph, or code snippet.
Provide relevant examples to guide the AI towards the desired style, structure, and content.
Use clear separators, to distinguish between different parts of the prompt, such as instructions, context, and examples.
Remember that prompt engineering is an iterative process, so continuously test and refine prompts based on the model's output.
Focus on instructing the model on what it should do rather than what it should avoid.
Finally, test prompts with different models to understand their varying sensitivities and responses
Frameworks for prompt design can also provide a structured approach. Advanced techniques, such as meta-prompting, can be used to guide the model itself in designing better prompts. AI frameworks like ScaleDown can automatically identify and remove irrelevant context from prompts before they reach the LLM. It does this by scanning prompts to identify which portions are necessary for the task at hand, addressing the "identification without exclusion" problem.
Conclusion
Extra details can degrade performance by reducing accuracy, coherence, and relevance, and LLMs often struggle to effectively filter out irrelevant information even when they can identify it. Employing both automatic and manual techniques for cleaning and optimizing prompts is crucial. Automatic methods offer efficiency and scalability for handling large volumes of prompts, while manual refinement allows for greater human oversight and the ability to address nuanced cases. A combination of both approaches often yields the best results.
[1] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
[2] Large Language Models Can Be Easily Distracted by Irrelevant Context https://openreview.net/pdf?id=JSZmoN03Op
[3] Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information https://arxiv.org/html/2408.10615v1
[4] Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales? https://openreview.net/pdf?id=FbuODM02ra
[5] Resilience of Large Language Models for Noisy Instructions https://arxiv.org/html/2404.09754v1
[6] How Easily do Irrelevant Inputs Skew the Responses of Large Language Models? https://openreview.net/pdf?id=S7NVVfuRv8
Dive in
Related
Video
Impact of LLMs on the Tech Stack and Product Development
By Anand Das • Nov 2nd, 2023 • Views 465
Video
LLMOps: The Emerging Toolkit for Reliable, High-quality LLM Applications
By Matei Zaharia • Jun 20th, 2023 • Views 4.2K
Video
Impact of LLMs on the Tech Stack and Product Development
By Anand Das • Nov 2nd, 2023 • Views 465
Video
LLMOps: The Emerging Toolkit for Reliable, High-quality LLM Applications
By Matei Zaharia • Jun 20th, 2023 • Views 4.2K