
Improve your MLflow experiment, keeping track of historical metrics

This blog was written by Stefano Bosisio What do we need today? Firstly, let’s think of the design of the main SDK protocol
March 14, 2023What do we need today?
Firstly, let’s think of the design of the main SDK protocol. The aim today is to allow data scientists to:
- add to a given experiment’s run the historical metrics computed in previous runs
- add custom computed metrics to a specific run
Thus, we can think of implementing the two following functions:
- report_metrics_to_experiment : this function will collect all the metrics from previous experiment’s runs and will group them in an interactive plot, so users can immediately spot issues and understand the overall trend
- report_custom_metrics : this function returns data scientists’ metrics annotations, posting a dictionary to a given experiment. This may be useful if a data scientist would like to stick to a specific experiment with some metrics on unseen data.
Report experiment runs metrics to the most recent run
This function makes use of the MLflowClient Client in MLflow Tracking manage experiments and their runs. From MLflowClient we can retrieve all the runs for a given experiment. From there, we can extract each run’s metrics. Once we gather together all the metrics we can proceed with a second step, where we are going to use plotly to have an interactive html plot. In this way, users can analyze each single data point for all the runs in the MLflow server artifacts box.
Fig.1 shows the first part of the report_metrics_to_experiment function. Firstly, the MlflowClient is initiated, with the given input tracking_uri . Then, the experiment’s information is retrieved with client.get_experiment_by_name and converted to a dictionary. From here each experiment’s run is listed, runs_list . Each run has its run_id which is practical to store metrics information in a dictionary models_metrics . Additionally, metrics can be accessed via run.to_dictionary()[‘data’][‘metrics’]. This value returns the name of the metric.
def report_metrics_to_experiment(self): r""" This function collects all the experiment runs'metrics and report them to the last run """ # initialise the MLflow client client = MlflowClient(tracking_uri=self.tracking_uri) # retrieve all the runs for the given experiment experiment = dict(client.get_experiment_by_name(self.experiment_name)) # from here retrieve all the runs runs_list = client.search_runs([experiment['experiment_id']]) # initialise a dictionary to get metrics for each run in the experiment models_metrics = {} # define the metrics to be plot in the most recent run metrics_to_plot = [] # collect all the run ids runs_id_to_plot = [] for run in runs_list: # retrieve run info run_dict = run.to_dictionary() single_run_id = run_dict['info']['run_id'] # record the run_id runs_id_to_plot.append(single_run_id) # extract the metrics metrics = run_dict['data']['metrics'] # retrieve historical metrics models_metrics[single_run_id] = {} for metric in metrics: # check if metric dictionary is populated if metric in metrics_to_plot: pass else: metrics_to_plot.append(metric) # retrieve all the data points for metric historical_metric = client.get_metric_history(single_run_id, metric) # if we have values populate the x and y_axis for this metric if historical_metric: x_axis = [] y_axis = [] for step in historical_metric: # the metric will be shown as a function of the number of steps step_n = dict(step)['step'] metric_n = dict(step)['value'] x_axis.append(step_n) y_axis.append(metric_n) # store values models_metrics[single_run_id][metric] = [x_axis, y_axis]Fig.1: First part of the function report_metrics_to_experiment. In this code snippet, I am showing how to retrieve metrics’ data points from the experiment’s runs. The final metrics values are stored in a dictionary, along with the run id, the metric’s steps, and values
From the metric’s name, the metric’s data points can be recorded through client.get_metric_history(). This attribute returns the steps and the values of the metric, so we can append to lists and saved them in models_metrics[single_run_id][metric] = [x_axis, y_axis]
Fig.2 shows the second part ofreport_metrics_to_experiment Firstly, a new plotly figure is initialized fig = go.Figure(). Metrics are then read from models_metrics and added as a scatter plot. The final plot is saved in html format, to have an interactive visualization.
# now for each of the value stored create a plot for metricsfig = go.Figure()# define the color palettecolorscale = px.colors.qualitative.Alphabet
for metric in metrics_to_plot: # the dictionary here can be called like # metrics_dict[run_id][metric][0] --> x axis [1] --> y_axis for cmap, run in enumerate(runs_id_to_plot, 0): # use a try-except in case some metrics may be missing from some experiments try: x_axis = models_metrics[run][metric][0] y_axis = models_metrics[run][metric][1] label = run px.line(x_axis, y_axis, ) fig.add_trace(go.Scatter(x=x_axis, y=y_axis, mode='lines+markers', name=label, line=dict(color=colorscale[cmap], width=2), ) ) except: pass # once all the metrics are done clean the plot fig.update_layout(xaxis_title='steps', yaxis_title=metric, font=dict(size=15) )
plot_name = metric + ".html" # runs_id_to_plot[0] is the latest experiment run_id client.log_figure(runs_id_to_plot[0], fig, plot_name) # clear plot fig.data = [] fig.layout = {}Fig.2: Second part of the function report_metrics_to_experiment. Here all the retrieved metrics are displayed on a plotly plot, which then saved in html format
Report custom metrics to a run
The final function we are going to implement today, reports a custom input to a specific run. In this case, a data scientist may have some metrics obtained from a run’s model with unseen data. This function is shown in fig.3. Given an input dictionary custom_metrics (e.g. {accuracy_on_datasetXYZ: 0.98} ) the function uses MlflowClient to log_metric for a specific run_id
def report_custom_metrics(self, custom_metrics): r"""This function report custom metrics to a run. For example in a model script data scientists may collect statistics and metrics after training with unseen datasets. They can create a metric dictionary and pass the input to this function to report those metrics to the run.
Parameters --------- custom_metrics: dictionary dictionary with all the metrics to log. e.g. {"accuracy_test":0.98, "beta_score_test":0.98} """ # set up the Mlflow Client client = MlflowClient(tracking_uri=self.tracking_uri) # log the metrics for key in custom_metrics: # retrieve metric value val = custom_metrics[key] client.log_metric(self.run_id, key, val)Fig.3: report_custom_metrics take an input dictionary, with unseen metrics or data, and it reports the key and val to the MLflow run with log_metric.
Update the experiment tracking interface
Now that two news functions have been added to the main MLflow protocol, let’s encapsulate them in ourexperiment_tracking_training.py In particular, end_training_job could call report_metrics_to_experiment , so, at the end of any training, we can keep track of all the historical metrics for a given experiment, as shown in fig.4
def end_training_job(experiment_tracking_params=None): r""" This function helps to complete an experiment. The function take the very last run of a given experiment family and reports artefacts and files
Parameters ------- experiment_tracking_params: dict, parameters for mlflow with the following keys: tracking_uri: str, tracking uri to run on mlflow (e.g. http://127.0.0.1:5000) tracking_storage: str, output path, this can be a local folder or cloud storage experiment_name: str, name of the model we're experimenting, run_name: str, name of the runner of the experiment tags: dict, specific tags for the experiment """ # set up the protocol runner = ExperimentTrackingInterface.ExperimentTrackingProtocol() runner.read_params(experiment_tracking_params) runner.set_tracking_uri() # check for any possible model which has not been saved - possibly due to mlflow experimental autlogs runner.log_any_model_file() # log all the historical metrics runner.report_metrics_to_experiment()Fig.4: report_metrics_to_experiment can be called at the end of any training job and added to the end_training_job functionality.
Additionally, to allow users to add their own metrics to specific runs, we can think of an add_metrics_to_run function, which receives as input the experiment tracking parameters, the run_id we want to work on, and the custom dictionary custom_metrics (fig.5):
def add_metrics_to_run(run_id, experiment_tracking_params, custom_metrics): r""" This function reports custom metrics to a specific run_id. For example, data scientists may compute some metrics against unseen dataset after training. To report metrics they need to use this function
Parameters ---------- run_id: str run_id of the run where metrics should be reported
experiment_tracking_params: dict, parameters for mlflow with the following keys: tracking_uri: str, tracking uri to run on mlflow (e.g. http://127.0.0.1:5000) tracking_storage: str, output path, this can be a folder or a cloud storage experiment_name: str, name of the model we're experimenting run_name: str, name of the runner of the experiment. tags: dict, specific tags for the experiment """ runner = ExperimentTrackingInterface.ExperimentTrackingProtocol() runner.read_params(experiment_tracking_params) runner.set_tracking_uri() runner.set_run_id(run_id) runner.report_custom_metrics(custom_metrics)Fig.5: Custom metrics can be reported through experiment_tracking_training.add_metrics_to_run module.
Create your final MLflow SDK and install it
Patching all the pieces together, the SDK package should be structured in a similar way:
mlflow_sdk/ mlflow_sdk/ __init__.py ExperimentTrackingInterface.py experiment_tracking_training.py requirements.txt setup.py README.mdThe requirements.txt contains all the packages we need to install our SDK, in particular, you’ll neednumpy, mlflow, pandas, matplotlib, scikit_learn, seaborn, plotly as default.
setup.py allows you to install your own MLflow SDK in a given Python environment and the script should be structured in this way:
from setuptools import setupfrom pathlib import Path
# read the requirementsrequirements_path = Path("requirements.txt")# extract all the requirements to installrequirements = requirements_path.read_text().split("\n") if requirements_path.exists() else ""# run the installation of our mlflow_sdksetup( name='mlflow_sdk', version='0.1', packages=['mlflow_sdk'], description='A wee description of your great mlflow_sdk', install_requires=requirements,)
Fig.6: Setup.py to install our mlflow_sdk package in a given Python environment
To install the SDK just use Python or a virtualenv Python as python setup.py install
SDK in action!
It’s time to put into action our MLflow SDK. We’ll test it with a sklearn.ensemble.RandomForestClassifierand the iris dataset¹ ² ³ ⁴ ⁵ (source and license, Open Data Commons Public Domain Dedication and License). Fig.7 shows the full example script we are going to use (my script name is 1_iris_random_forest.py)
tracking_params contains all the relevant info for setting up the MLflow server, as well as the run and experiment name. After loading the dataset, we are going to create a train test split with sklearn.model_selection.train_test_split . To show different metrics and plots in the MLflow artifacts I run 1_iris_random_forest.py 5 times, varying the test_size with the following values:0.3, 0.2, 0.1, 0.05, 0.01
import osimport pandas as pdfrom sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom mlflow_sdk import experiment_tracking_training
# Define mlflow paramstracking_params ={ 'tracking_uri':'http://127.0.0.1:5000', # use your local aaddress or a server one 'tracking_storage':'mlruns', # we're going to save locally these results otherwise use a cloud_storage 'run_name': 'random_forest_iris', # the name of the experiment's run 'experiment_name':'random_forest', # the name of the experiment 'tags':None,}
# load the iris datasetiris = datasets.load_iris()data=pd.DataFrame({ 'sepal length':iris.data[:,0], 'sepal width':iris.data[:,1], 'petal length':iris.data[:,2], 'petal width':iris.data[:,3], 'species':iris.target})
# divide features and labelsX=data[['sepal length', 'sepal width', 'petal length', 'petal width']] # Featuresy=data['species'] # Labels# Split dataset into training set and test setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% test# Random Forestclf=RandomForestClassifier(n_estimators=2)# input parameters for the modelparams={'X': X_train, 'y': y_train}# I want to save all the artefacts locally as welloutput_folder = os.getcwd() + '/outputs'# retrieve the test labelstest_labels = y_test.unique()# run the training and fitrun_id = experiment_tracking_training.start_training_job(experiment_tracking_params=tracking_params)clf.fit(**params)# end the trainingexperiment_tracking_training.end_training_job(experiment_tracking_params=tracking_params)# as a test case add fake metricsfalse_metrics = {"test_metric1":0.98, "test_metric2":0.00, "test_metric3":50}experiment_tracking_training.add_metrics_to_run(run_id, tracking_params, false_metrics)Fig.7: In the example, we are going to run a random forest against the iris dataset. The MLflow SDK will keep track of the model info during training and report all the additional metrics with add_metrics_to_run.
Once the data have been set up, clf=RandomForestClassifier(n_estimators=2) we can call experiment_tracking_training.start_training_job. This module will interact with the MLflow context manager and it will report to the MLflow server the script that is running the model as well as the model’s info and artifacts.
At the end of the training, we want to report all the experiment run’s metrics in a single plot and, just for testing, we are going to save also some “fake” metrics like false_metrics = {“test_metric1”:0.98, … }
Before running the 1_iris_random_forest.pyin a new terminal tab open up the connection with the MLflow server as mlflow ui and navigate to http://localhost:5000 orhttp://127.0.0.1:5000 . Then, run the example above aspython 1_iris_random_forest.py and repeat the run 5 times for different values of test_size
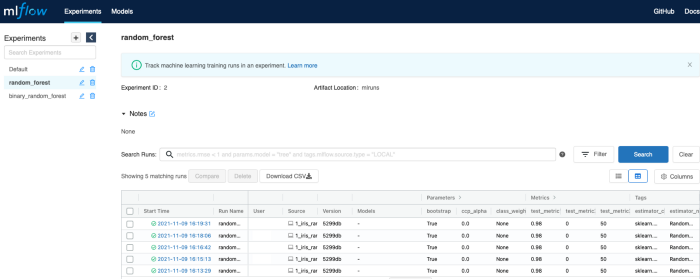
Fig.8: MLflow UI after running the example script
Fig.8 should be similar to what you have after running the example script. Under Experiments the experiments’ names are listed. For each experiment there is a series of runs, in particular, under random_forest you’ll find your random forest runs, from 1_iris_random_forest.py
For each run we can immediately see some parameters, which are automatically logged by mlflow.sklearn.autolog() as well as our fake metrics (e.g. test_metric1 ) The autolog function saves also Tags , reporting the estimator class (e.g. sklearn.ensemble._forest.RandomForestClassifier) and method ( RandomForestClassifier ).
Clicking on a single run more details are shown. At first, you’ll see all the model parameters, which, again, are automatically reported by the autolog function. Scrolling down the page we can access the Metrics plots. In this case, we have just a single data point, but you can have a full plot as a function of the number of steps for more complicated models.
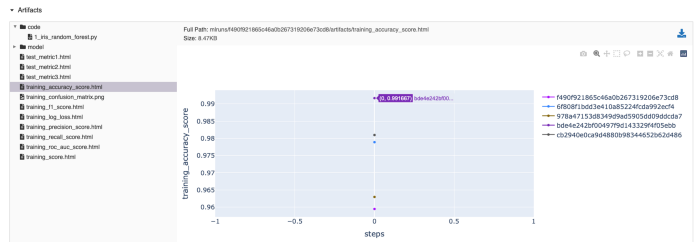
Fig.9: Artifacts saved by MLflow SDK. In the artifacts box, you can find the code used to run the model (in my case 1_iris_random_forest.py) as well as the model pickle files under model folder and all the interactive metrics plots as well as the confusion matrix.
The most important information will then be stored under the Artifacts box (fig.9). Here you can find different folders which have been created by our mlflow_sdk:
- Firstly, code is a folder that stores the script used to run our model — this was done in experiment_tracking_training on line 24 with traceback , here the link, and pushed to MLflow artifacts on line 31 of run_training function, here the link).
- Following, model stores binary pickle files. MLflow automatically saves model files as well as their requirements to allow the reproducibility of the results. This will be super helpful at deployment time.
- Finally, you’ll see all the interactive plots. ( *.html ), generated at the end of the training, as well as additional metrics we have computed during the training, such as training_confusion_matrix.png
As you can see, with minimal intervention we have added a full tracking routing to our ML models. Experimenting is crucial at development time and in this way, data scientists could easily use MLflow Tracking functionality without over-modifying their existing codes. From here you can explore different “shades” of reports, adding further information for each run as well as running MLflow on a dedicated server to allow cross-team collaboration.
Author’s Bio: Stefano is a Machine Learning Engineer at Trustpilot, based in Edinburgh. Stefano helps data science teams to have a smooth journey from model prototyping to model deployment. Stefano’s background is Biomedical Engineering (Polytechnic of Milan) and a Ph.D in Computational Chemistry (University of Edinburgh).
Popular
Dive in
Related
Video
Product Metrics are LLM Evals // Raza Habib CEO of Humanloop
By Raza Habib • Jun 3rd, 2025 • Views 358
Video
A Systematic Approach to Improve Your AI Powered Applications
By Karthik Kalyanaraman • Aug 8th, 2024 • Views 212
Video
A Systematic Approach to Improve Your AI Powered Applications
By Karthik Kalyanaraman • Aug 8th, 2024 • Views 212
Video
Product Metrics are LLM Evals // Raza Habib CEO of Humanloop
By Raza Habib • Jun 3rd, 2025 • Views 358