
MLflow on AWS with Pulumi: A Step-by-Step Guide
# AWS
# MLFlow
# MLops
# Pulumi
Many data science and machine learning teams grapple with the challenge of effectively tracking numerous experiments and their corresponding results
March 13, 2024
Bojan Jakimovski
Many data science and machine learning teams grapple with the challenge of effectively tracking numerous experiments and their corresponding results. Often, they resort to using cumbersome methods such as Excel spreadsheets and manual record-keeping, leading to overwhelming data management and hindering collaboration within the team.
This manual approach not only consumes valuable time and effort but also introduces the risk of errors and inconsistencies. Moreover, teams may encounter difficulties in reproducing experiments, retrieving specific model versions, and managing model versioning effectively.
These challenges can impede the scalability and reproducibility of the machine learning workflows, highlighting the crucial need for a more streamlined and automated solution like MLflow, which offers comprehensive experiment tracking, model versioning, and collaboration tools to alleviate these pain points and foster greater efficiency and teamwork within data science projects.
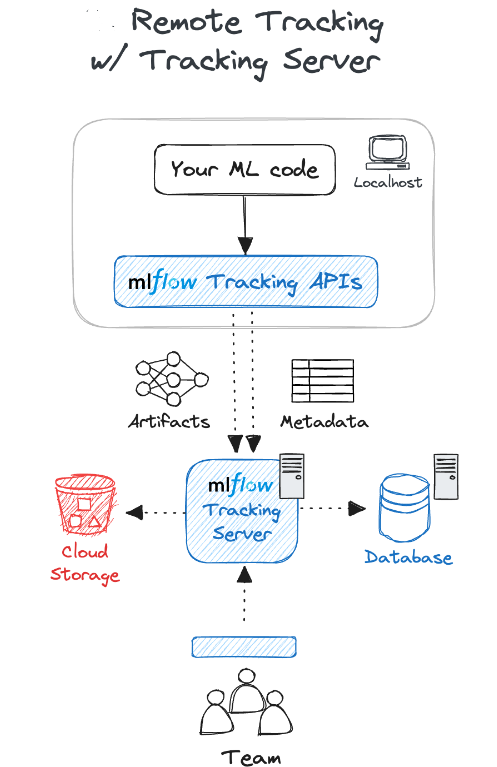
In this tutorial, we’ll demonstrate how to deploy an MLflow tracking server on AWS using Pulumi. Pulumi allows us to configure AWS cloud resources easily by creating infrastructure with Python code. By automating the deployment process, we eliminate manual configuration errors and ensure a scalable, reproducible environment for our machine learning projects.
Step 0: Prerequisites and Installation
Before proceeding with this tutorial, ensure that you have the following prerequisites installed:
- Python: This tutorial uses Python for scripting and configuration. Make sure Python is installed on your system. You can download Python from the official Python website: https://www.python.org/downloads/ .
- Pulumi: Pulumi is required to define and manage cloud infrastructure using code. Install Pulumi by following the instructions provided on the official Pulumi website: https://www.pulumi.com/docs/get-started/install/ .
- AWS CLI: The AWS Command Line Interface (CLI) is necessary to interact with AWS services. Install the AWS CLI by following the instructions provided on the official AWS documentation: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html .
- Admin IAM credentials: Ensure you have an AWS account and IAM (Identity and Access Management) credentials set up. You will need an access key ID and a secret access key to authenticate the AWS CLI with your AWS account.
Once you have installed these prerequisites, you’ll be ready to deploy the MLflow tracking server on AWS using Pulumi.
Step 1: Creating Pulumi Project
The first step needed is to create a directory for the Pulumi project and initialize the default Pulumi project:
Step 2: Install the necessary Python packages
Install the required Python packages for working with Pulumi, which will allow us to interact with AWS services:
Step 3.1: Create the services directory and Python files
Navigate to your Pulumi project directory if you’re not already there and create a directory named services, then navigate into the directory and create 3 Python files named ec2.py, s3.py, rds.py:
Step 3.2.1: Define the S3 artifact storage code
We are defining the code needed for creating an S3 storage-bucket responsible for storing the artifacts from the MLflow tracking server. To define the bucket, we need to provide two parameters: the name of the bucket and the access control list (preferably private). This code is located in the s3.py file.
Step 3.2.2: Define the RDS Metadata Database code
The next step is to define the code required for setting up the RDS database, which stores the metadata of the experiments. Firstly, we need to define the creation of a dedicated RDS subnet to facilitate communication between the server (EC2) and the RDS server. This special subnet ensures secure and efficient data transfer. Following the definition of the creation of the subnet, we define the RDS server. We opt for running a Postgres database version 13.8 on the smallest, most cost-effective instance, db.t3.micro. For more details about the parameters needed for the code, refer to the docstrings of the functions.
Step 3.2.3: Define EC2 code
The crucial step in this process is defining the EC2 virtual server, which will host the MLflow remote tracking server. Before proceeding, ensure that you have already defined the code for a Virtual Private Cloud (VPC) to provide network isolation. Within the VPC, it’s essential to establish a subnet network dedicated to handling communication with the EC2 instance, so we need to define the code for subnet networks.
Additionally, we need to define the configuring of an Internet Gateway to enable internet access for the EC2 instance. This access is vital for ML engineers and data scientists to interact with the server, send experiments, and access artifacts. To control access and ensure security, define a Security Group specifying which traffic types, protocols, ports, and IP addresses are allowed.
Once these elements are defined, proceed to define the code for creating the EC2 instance. Opt for the t2.micro instance type, which falls under the free tier and is the most economical option. Also, define the creation of a routing table and add a route for internet access to enable seamless communication with the outside world.
Step 3.4: Define the services in the __main__.py file
Now when all the elements are defined with code, we need to create them by using the__main__.py script. The next step is calling all the building code blocks within the __main__.py file.
We need to import all the functions which define the elements for each of the AWS services we are going to use. The first elements that are going to be created are the Virtual Private Cloud (VPC) which will use the 10.0.0.1/16 CIDR block and two subnet networks that will use different subregions(availability zones) and CIDR blocks.
After that we are creating the internet gateway and creating the security groups for secure access to the EC2 instance. We are going to allow all the inbound traffic on port 22, for SSH traffic, all traffic on port 80 for HTTP, port 5000 on which the MLlflow tracking server will work and port 443 which is allocated for HTTPS traffic. Also we are going to allow outbound traffic on all ports and IP addresses.
After that we are creating the ec2 instance on which the MLlflow tracking server will be hosted. The EC2 will use the free t2.micro instance type which is enough for a MLflow tracking server. We also need to use the correct AMI for an Ubuntu Linux machine. This one depends on the region you are hosting your EC2 server. Our server needs to have an public IPv4 address so it can be accessed via the outside world. We need to allow internet access to the EC2 server by configuring the routing in the route table.
Creating the RDS subnet and the security group for the RDS by allowing all the inbound traffic on port 5432.
After configuring and creating the EC2 server, we need to create a RDS server on which the PostgreSQL database will live on. We are defining the name of the database, username and password.
After creating the RDS we are creating the S3 bucket that is needed for storing the artifacts.
And the last step is to export all the metadata needed for the resources we created.
Now all it needs to be done is to do the deployment of the infrastructure with running the following command:
Another little bit more advanced option is deploying the cloud infrastructure using GitHub Actions. That option will be shown only in the GitHub Repository with the code for this tutorial.
Step 4: Install Requirements, setup reverse proxy server & authentication, start the remote tracking server
After the successful creation of the AWS cloud infrastructure needed for the MLflow tracking server, the next step is to connect to the EC2 instance, to install the needed requirements, to set up a reverse proxy server & authentication, and lastly to start the remote tracking server.
Step 4.1: Connect to EC2 instance
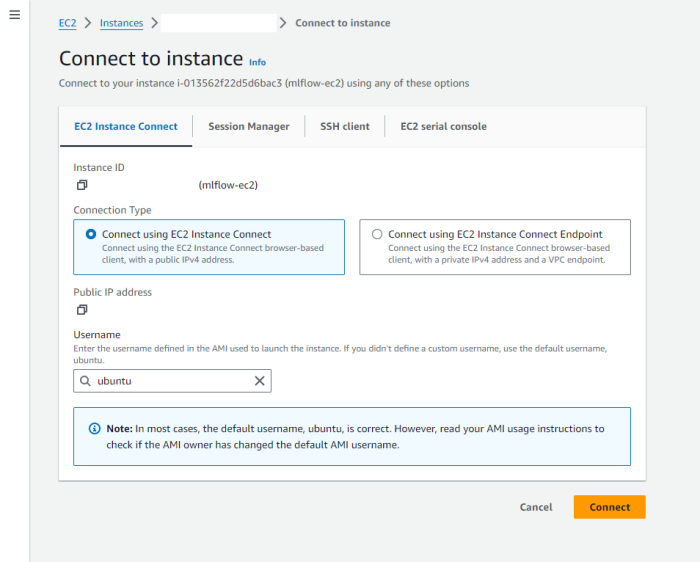
There are two possibilities to connect to the EC2 instance, via the SSH from your local machine or via the AWS console. For this tutorial, we will go with the AWS console approach:
Step 4.2: Install requirements
The next step is to install all the requirements needed for the MLflow tracking server. So we first need to update/upgrade the OS with all the latest packages. After that we need to install the pip for python. Using pip we are installing the mlflow. Also we are required to install apache2-utils for setting up basic authentication and after that we need nginx which will be used for reverse proxy server and authentication.
Step 4.3: Configure the reverse proxy and authentication
We need to configure the nginx.conf file to listen on port 80 and to have basic authentication using the passwords from the /etc/nginx/.htpasswd file. To access the NGINX config file, this command needs to be run:
The file content is this:
After modifying the nginx.conf file, we need to reload the nginx service.
After reloading the nginx service, we are going to create an user called MlflowUser for which we are going to add a password by running the command:
Step 4.4: Run the MLflow
The last phase is to launch the MLflow Tracking Server, by running this command:
Step 5: Access the MLflow Remote Tracking Server UI
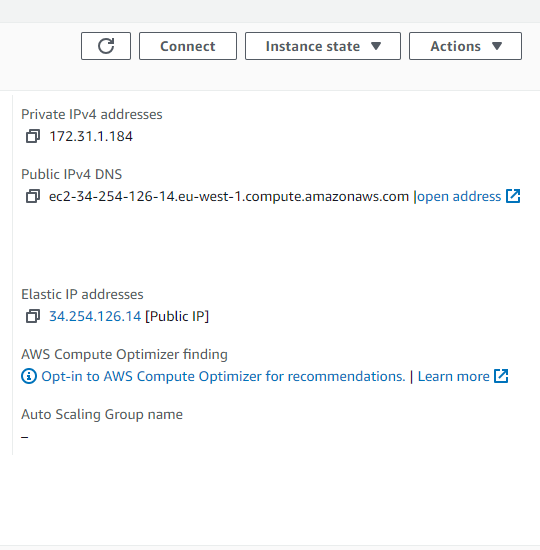
To access the UI for the MLFlow Remote Tracking Server, you can use the AWS console for EC2 and find the Public IPv4 DNS address.
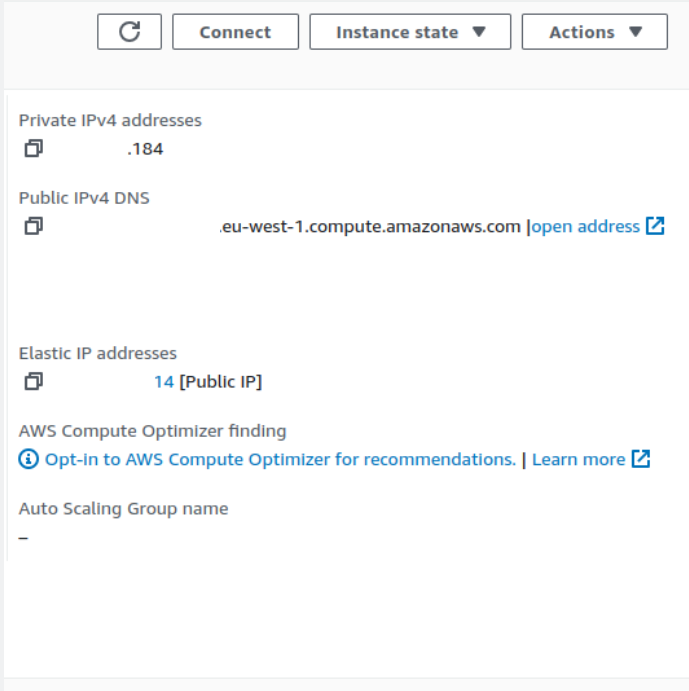
After locating the Public IPv4 DNS address, you can open that address in the browser and allow you to access the MLflow UI.
Step 6: Using the MLflow Remote Tracking Server
In this tutorial we are going to have two examples:
- Classical supervised machine learning pipeline
- Evaluation pipeline for LLM
The classical supervised machine learning pipeline is a simple experiment where we are working with the iris dataset, which is split into train and test datasets. On that dataset we are training a Random Forest Classifier, getting the parameters for the model, the accuracy metric, confusion matrix (which we are saving as a .png), and all of those information is logged on the MLFlow Remote Tracking Server:
The LLM evaluation pipeline is an example of evaluating the model of GPT-4 on a small dataset with given inputs and ground truth. The results of the evaluation are stored in a pandas dataframe which is logged on the MLflow Remote Tracking Server.
Conclusion
This configuration facilitates easy access to the MLflow server for all team members, allowing them to contribute experiments to the central platform from their respective systems. Such a configuration fosters smooth collaboration, streamlined organization, and accurate experiment tracking within the data science team.
Dive in
Related
Blog
How to Build Your First Semantic Search System: My Step-by-Step Guide with Code
By Sonam Gupta • Jan 5th, 2024 • Views 1.1K
Video
GenAI in production with MLflow // Ben Wilson // DE4AI
By Ben Wilson • Sep 17th, 2024 • Views 1.7K
Blog
How to Build Your First Semantic Search System: My Step-by-Step Guide with Code
By Sonam Gupta • Jan 5th, 2024 • Views 1.1K
Video
GenAI in production with MLflow // Ben Wilson // DE4AI
By Ben Wilson • Sep 17th, 2024 • Views 1.7K